 |
| Experiment So Far |
 |
| Automobile Price Data (Clean) 1 |
 |
| Automobile Price Data (Clean) 2 |
To finish this experiment, let's take a look at Cross-Validation. We briefly touched on this topic in a previous post as it relates to Classification models. Let's dig a little deeper into it.
As we've mentioned before, it is extremely important to have a separation between Training data (data used to train the model) and Testing data (data used to evaluate the model). This separation is necessary because it allows us to determine how well our model could predict "new" data. In this case, "new" data is data that the model has not seen before. If we were to train the model using a data set, then evaluate the model using the same data set, we would have no way to determine whether they model is good at fitting "new" data or only good at fitting data it has already seen.
In practice, these data sets are often created by cleaning and preparing a single data set that contains all of the variables needed for modelling, as well as a column or columns containing the results we are trying to predict. Then, this data is split into two data sets. This process is generally random, with a larger portion of the data going to the training set than to the testing set. However, this methodology has a major flaw. How do we know if we got a bad sample? What if by random chance, our training data was missing a significant pattern that existed in our testing set, or vice-versa? This could cause us to inappropriately identify our model as "good" due to something that is entirely outside of our control. This is where Cross-Validation comes into play.
Cross-Validation is a process for creating multiple sets of testing and training sets, using the same set of data. Imagine that we split our data in half. For the first model, we train the model using the first half of the data, then we test the model using the second half of the data. Turns out that we can repeat this process by swapping the testing and training sets. So, we can train the second model using the second half of the data, then test the model using the first half of the data. Now, we have two models trained with different training sets and tested with different testing sets. Since the two testing sets did not contain any of the same elements, we can combine the scored results together to create a master set of scored data. This master set of scored data will have a score for every record in our original data set, without ever having a single model score a record that it was trained with. This greatly reduces the chances of getting a bad sample because we are effectively scoring every element in our data, not just a small portion.
Let's expand this method a little. First, we need to break our data into three sets. The first model is trained using sets 1 and 2, and tested using set 3. The second model is trained using sets 1 and 3, and tested using set 2. The third model is trained using sets 2 and 3, and tested using set 1. In practice, the sets are known as "folds". As you can see, we can extend this method out as far as we would like to create a master set of predictions.
 |
| K Fold Cross-Validation |
Now, the question becomes "How many folds should I have? 5? 10? 20? 1000?" This is a major question that some data scientists spend quite a bit of time working with. Fortunately for us, Azure ML automatically uses 10 folds, so we don't have to worry too much about this question. Let's see it in action.
If we look back at our previous post, we can see that the normalization did not improve any of our models. So, for simplicity, let's remove normalization.
 |
| Experiment So Far (No Normalization) |
 |
| Cross Validate Model |
 |
| Evaluation Results by Fold |
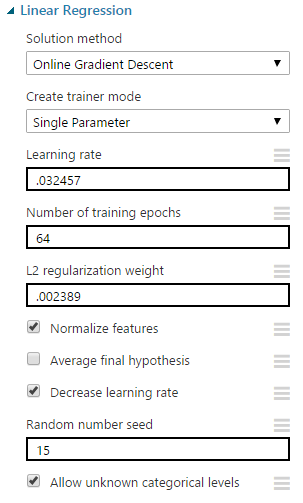
Next, we have to consider which model to input into the Cross-Validation. The issue here is that the Cross Validate Model module requires an untrained data set, while the Tune Model Hyperparameters module outputs a trained data set. So, in order to use our tuned models from the previous posts, we'll need to manually copy the tuned parameters from the Tune Model Hyperparameters module into the untrained model modules.
 |
| Online Gradient Descent Linear Regression Tuned Parameters |
 |
| Online Gradient Descent Linear Regression |
 |
| Ordinary Least Squares Linear Regression vs Online Gradient Descent Linear Regression |
 |
| Boosted Decision Tree Regression vs. Poisson Regression |
Hopefully, this series opened your mind as to the possibilities of Regression in Azure Machine Learning. Stay tuned for more posts. Thanks for reading. We hope you found this informative.
Brad Llewellyn
Data Scientist
Valorem
@BreakingBI
www.linkedin.com/in/bradllewellyn
llewellyn.wb@gmail.com
No comments:
Post a Comment