Today, we will talk about creating Double and Triple Exponential Time Series using Tableau 8.1's new R functionality. If you read our previous post,
Single Exponential Time Series, you remember that we were only able to predict a constant value for all future observations. Trend and Seasonality were not considered using the Single Exponential. These models should fix all of that. Once again, we will use the Superstore Sales sample data set from Tableau.
At its core, a single exponential time series can predict values without trend (increase or decrease over longer periods of time) or seasonality (repetition of patterns at regular intervals, i.e. yearly, monthly, etc.). The double exponential time series adds trend to the model while the triple exponential time series adds trend and seasonality. We're also adding the model that accounts for seasonality without accounting for trend. We're not sure what this model is called, so we'll call it the Reverse Double Exponential Model for now. If you have any idea what it's called or if it's invalid for some reason, please let us know in the comments. The code is almost identical like before, just with the second to last line changed. You can find the full code in the appendix at the end of this post.
Double Exponential
fit <- HoltWinters(timeser, gamma=FALSE)
Reverse Double Exponential
fit <- HoltWinters(timeser, beta=FALSE)
Triple Exponential
fit <- HoltWinters(timeser)
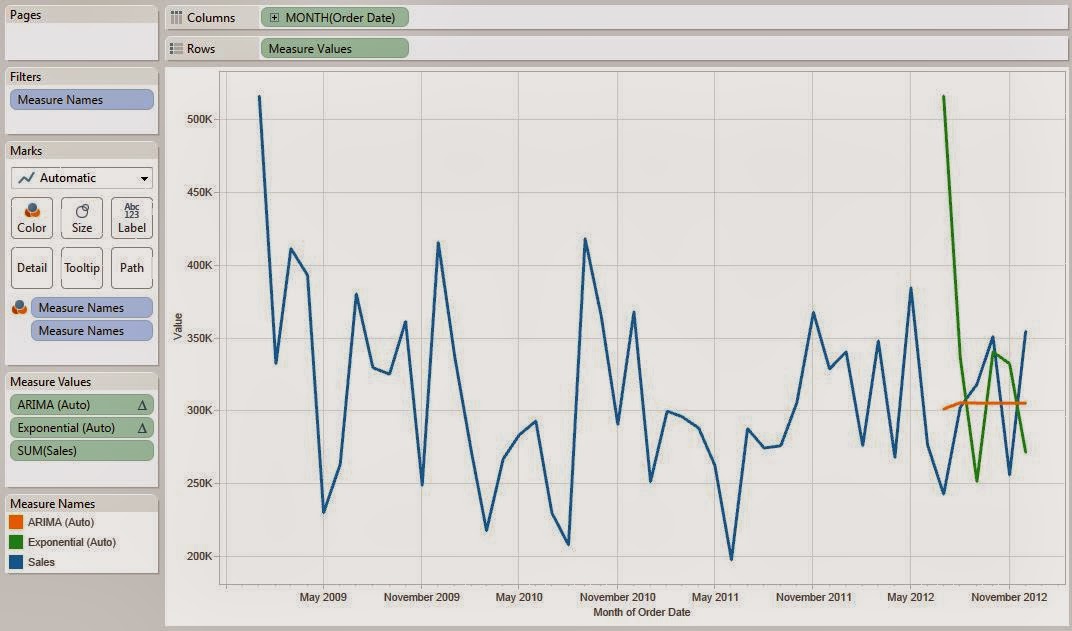
Now, let's look at these predictions.
.JPG) |
| Sales by Month (Predictions) |
We can see that the green line (Double Exponential) is straight. This is exactly what we expected. However, there is some definite seasonality in this data that we need to account for. The orange line (Triple Exponential) seems to follow that seasonality, but the trend seems to have pushed it too high. The red line (Reverse Double Exponential) appears to be the "Goldilocks" model. It accounts for the seasonality, but doesn't let the trend drag it too high. For further examination, let's look at the 95% confidence intervals for these models to see which models fit the data more tightly.
.JPG) |
| Sales by Month (Bounds) |
We can easily see that the green bounds (Double Exponential) are so spread out that they become basically worthless. Also, the orange bounds (Triple Exponential) and the red bounds (Reverse Double Exponential) seem to the same except that the orange bounds are shifted up slightly higher, which is exactly what we saw with the predictions as well. Therefore, we have good evidence to say that the Reverse Double Exponential model is the best fit for this data. Now, let's use the same trick as last week to predict new values by adding blank rows to our data set.
.JPG) |
| Sales by Month (Reverse Double Exponential with Bounds) |
Now, we have seemingly accurate predictions using a well-respected time series model. However, we're not done with this yet. There are other families of time series models we could use. There's also artificial neural networks, naive bayes, and much more. Thanks for reading. We hope you found this informative.
Brad Llewellyn
Data Analytics Consultant
Mariner, LLC
llewellyn.wb@gmail.com
https://www.linkedin.com/in/bradllewellyn
Appendix
Double Exponential
SCRIPT_REAL("
library(forecast)
## Creating vectors
hold.orig <- .arg4
len.orig <- length( hold.orig )
len.new <- len.orig - hold.orig[1]
year.orig <- .arg1
month.orig <- .arg2
sales.orig <- .arg3
## Sorting the Data
date.orig <- year.orig + month.orig / 12
dat.orig <- cbind(year.orig, month.orig, sales.orig)[sort(date.orig, index.return = TRUE)$ix,]
dat.new <- dat.orig[1:len.new,]
## Fitting the Time Series
timeser <- ts(dat.new[,3], start = c(dat.new[1,1], dat.new[1,2]), end = c(dat.new[len.new,1], dat.new[len.new,2]), frequency = 12)
fit <- HoltWinters(timeser, gamma=FALSE)
c(rep(NA,len.new), forecast(fit, hold.orig[1])$mean)
"
, ATTR( YEAR( [Order Date] ) ), ATTR( MONTH( [Order Date] ) ), SUM( [Sales] ),
[Months to Forecast] )
Double Exponential (Lower 95%)
SCRIPT_REAL("
library(forecast)
## Creating vectors
hold.orig <- .arg4
len.orig <- length( hold.orig )
len.new <- len.orig - hold.orig[1]
year.orig <- .arg1
month.orig <- .arg2
sales.orig <- .arg3
## Sorting the Data
date.orig <- year.orig + month.orig / 12
dat.orig <- cbind(year.orig, month.orig, sales.orig)[sort(date.orig, index.return = TRUE)$ix,]
dat.new <- dat.orig[1:len.new,]
## Fitting the Time Series
timeser <- ts(dat.new[,3], start = c(dat.new[1,1], dat.new[1,2]), end = c(dat.new[len.new,1], dat.new[len.new,2]), frequency = 12)
fit <- HoltWinters(timeser, gamma=FALSE)
c(rep(NA,len.new), forecast(fit, hold.orig[1])$lower[,2])
"
, ATTR( YEAR( [Order Date] ) ), ATTR( MONTH( [Order Date] ) ), SUM( [Sales] ),
[Months to Forecast] )
Double Exponential (Upper 95%)
SCRIPT_REAL("
library(forecast)
## Creating vectors
hold.orig <- .arg4
len.orig <- length( hold.orig )
len.new <- len.orig - hold.orig[1]
year.orig <- .arg1
month.orig <- .arg2
sales.orig <- .arg3
## Sorting the Data
date.orig <- year.orig + month.orig / 12
dat.orig <- cbind(year.orig, month.orig, sales.orig)[sort(date.orig, index.return = TRUE)$ix,]
dat.new <- dat.orig[1:len.new,]
## Fitting the Time Series
timeser <- ts(dat.new[,3], start = c(dat.new[1,1], dat.new[1,2]), end = c(dat.new[len.new,1], dat.new[len.new,2]), frequency = 12)
fit <- HoltWinters(timeser, gamma=FALSE)
c(rep(NA,len.new), forecast(fit, hold.orig[1])$upper[,2])
"
, ATTR( YEAR( [Order Date] ) ), ATTR( MONTH( [Order Date] ) ), SUM( [Sales] ),
[Months to Forecast] )
Reverse Double Exponential
SCRIPT_REAL("
library(forecast)
## Creating vectors
hold.orig <- .arg4
len.orig <- length( hold.orig )
len.new <- len.orig - hold.orig[1]
year.orig <- .arg1
month.orig <- .arg2
sales.orig <- .arg3
## Sorting the Data
date.orig <- year.orig + month.orig / 12
dat.orig <- cbind(year.orig, month.orig, sales.orig)[sort(date.orig, index.return = TRUE)$ix,]
dat.new <- dat.orig[1:len.new,]
## Fitting the Time Series
timeser <- ts(dat.new[,3], start = c(dat.new[1,1], dat.new[1,2]), end = c(dat.new[len.new,1], dat.new[len.new,2]), frequency = 12)
fit <- HoltWinters(timeser, beta=FALSE)
c(rep(NA,len.new), forecast(fit, hold.orig[1])$mean)
"
, ATTR( YEAR( [Order Date] ) ), ATTR( MONTH( [Order Date] ) ), SUM( [Sales] ),
[Months to Forecast] )
Reverse Double Exponential (Lower 95%)
SCRIPT_REAL("
library(forecast)
## Creating vectors
hold.orig <- .arg4
len.orig <- length( hold.orig )
len.new <- len.orig - hold.orig[1]
year.orig <- .arg1
month.orig <- .arg2
sales.orig <- .arg3
## Sorting the Data
date.orig <- year.orig + month.orig / 12
dat.orig <- cbind(year.orig, month.orig, sales.orig)[sort(date.orig, index.return = TRUE)$ix,]
dat.new <- dat.orig[1:len.new,]
## Fitting the Time Series
timeser <- ts(dat.new[,3], start = c(dat.new[1,1], dat.new[1,2]), end = c(dat.new[len.new,1], dat.new[len.new,2]), frequency = 12)
fit <- HoltWinters(timeser, beta=FALSE)
c(rep(NA,len.new), forecast(fit, hold.orig[1])$lower[,2])
"
, ATTR( YEAR( [Order Date] ) ), ATTR( MONTH( [Order Date] ) ), SUM( [Sales] ),
[Months to Forecast] )
Reverse Double Exponential (Upper 95%)
SCRIPT_REAL("
library(forecast)
## Creating vectors
hold.orig <- .arg4
len.orig <- length( hold.orig )
len.new <- len.orig - hold.orig[1]
year.orig <- .arg1
month.orig <- .arg2
sales.orig <- .arg3
## Sorting the Data
date.orig <- year.orig + month.orig / 12
dat.orig <- cbind(year.orig, month.orig, sales.orig)[sort(date.orig, index.return = TRUE)$ix,]
dat.new <- dat.orig[1:len.new,]
## Fitting the Time Series
timeser <- ts(dat.new[,3], start = c(dat.new[1,1], dat.new[1,2]), end = c(dat.new[len.new,1], dat.new[len.new,2]), frequency = 12)
fit <- HoltWinters(timeser, beta=FALSE)
c(rep(NA,len.new), forecast(fit, hold.orig[1])$upper[,2])
"
, ATTR( YEAR( [Order Date] ) ), ATTR( MONTH( [Order Date] ) ), SUM( [Sales] ),
[Months to Forecast] )
Triple Exponential
SCRIPT_REAL("
library(forecast)
## Creating vectors
hold.orig <- .arg4
len.orig <- length( hold.orig )
len.new <- len.orig - hold.orig[1]
year.orig <- .arg1
month.orig <- .arg2
sales.orig <- .arg3
## Sorting the Data
date.orig <- year.orig + month.orig / 12
dat.orig <- cbind(year.orig, month.orig, sales.orig)[sort(date.orig, index.return = TRUE)$ix,]
dat.new <- dat.orig[1:len.new,]
## Fitting the Time Series
timeser <- ts(dat.new[,3], start = c(dat.new[1,1], dat.new[1,2]), end = c(dat.new[len.new,1], dat.new[len.new,2]), frequency = 12)
fit <- HoltWinters(timeser)
c(rep(NA,len.new), forecast(fit, hold.orig[1])$mean)
"
, ATTR( YEAR( [Order Date] ) ), ATTR( MONTH( [Order Date] ) ), SUM( [Sales] ),
[Months to Forecast] )
Triple Exponential (Lower 95%)
SCRIPT_REAL("
library(forecast)
## Creating vectors
hold.orig <- .arg4
len.orig <- length( hold.orig )
len.new <- len.orig - hold.orig[1]
year.orig <- .arg1
month.orig <- .arg2
sales.orig <- .arg3
## Sorting the Data
date.orig <- year.orig + month.orig / 12
dat.orig <- cbind(year.orig, month.orig, sales.orig)[sort(date.orig, index.return = TRUE)$ix,]
dat.new <- dat.orig[1:len.new,]
## Fitting the Time Series
timeser <- ts(dat.new[,3], start = c(dat.new[1,1], dat.new[1,2]), end = c(dat.new[len.new,1], dat.new[len.new,2]), frequency = 12)
fit <- HoltWinters(timeser)
c(rep(NA,len.new), forecast(fit, hold.orig[1])$lower[,2])
"
, ATTR( YEAR( [Order Date] ) ), ATTR( MONTH( [Order Date] ) ), SUM( [Sales] ),
[Months to Forecast] )
Triple Exponential (Upper 95%)
SCRIPT_REAL("
library(forecast)
## Creating vectors
hold.orig <- .arg4
len.orig <- length( hold.orig )
len.new <- len.orig - hold.orig[1]
year.orig <- .arg1
month.orig <- .arg2
sales.orig <- .arg3
## Sorting the Data
date.orig <- year.orig + month.orig / 12
dat.orig <- cbind(year.orig, month.orig, sales.orig)[sort(date.orig, index.return = TRUE)$ix,]
dat.new <- dat.orig[1:len.new,]
## Fitting the Time Series
timeser <- ts(dat.new[,3], start = c(dat.new[1,1], dat.new[1,2]), end = c(dat.new[len.new,1], dat.new[len.new,2]), frequency = 12)
fit <- HoltWinters(timeser)
c(rep(NA,len.new), forecast(fit, hold.orig[1])$upper[,2])
"
, ATTR( YEAR( [Order Date] ) ), ATTR( MONTH( [Order Date] ) ), SUM( [Sales] ),
[Months to Forecast] )


.JPG)

.JPG)
.JPG)
.JPG)

.JPG)
.JPG)


.JPG)
.JPG)
.JPG)