|
| Forecast |
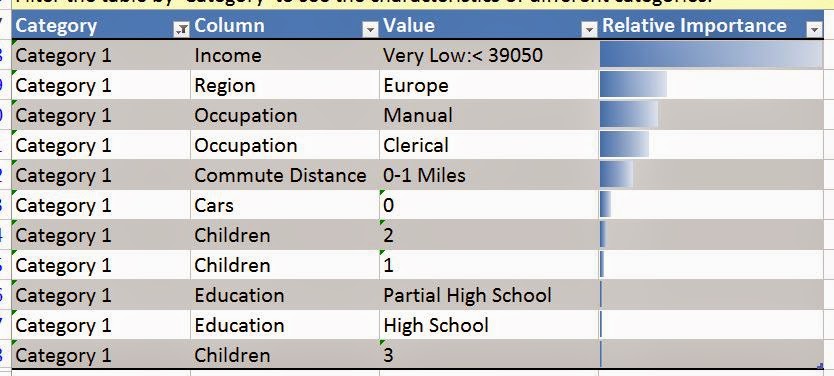
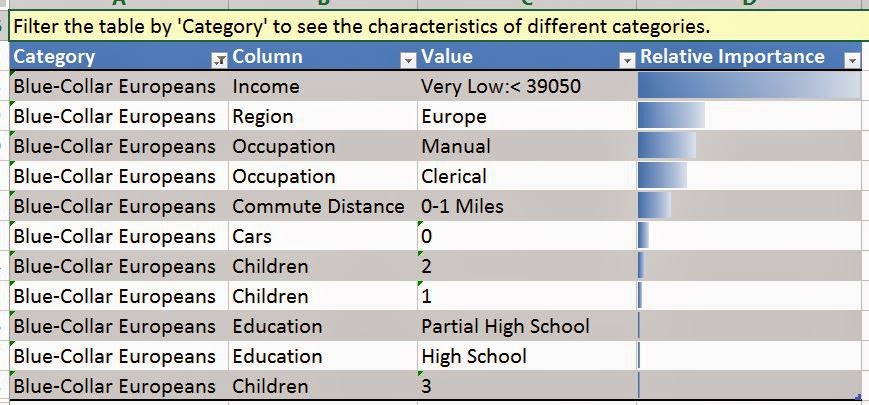
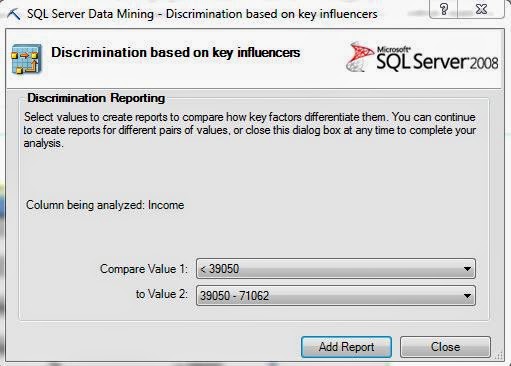
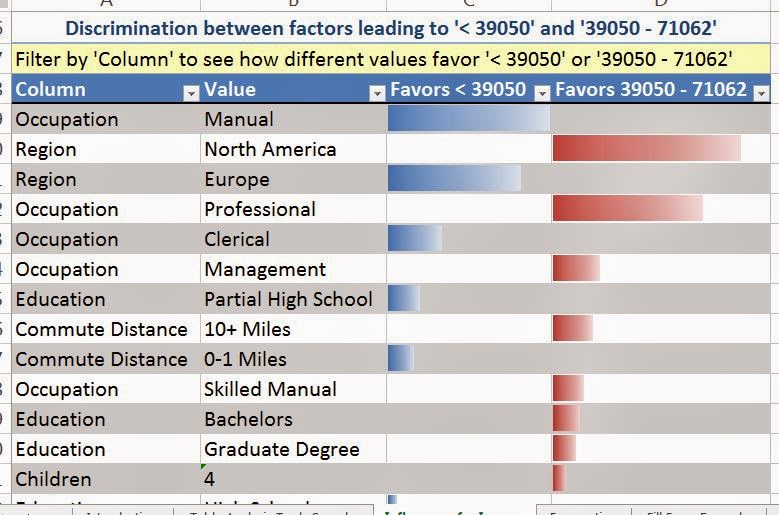
In general, the Table Analysis Tools are narrower versions of the algorithms in Analysis Services. The bad thing about this is that there is no tweaking available within the Table Analysis Tools Forecasting algorithm. If you want to play with the results, you will either need to use the Data Mining Forecasting algorithm in Excel, which we cover in a later post, or Analysis Services, which we may or may not cover. Now, let's take a look at the data.
 |
| Data |
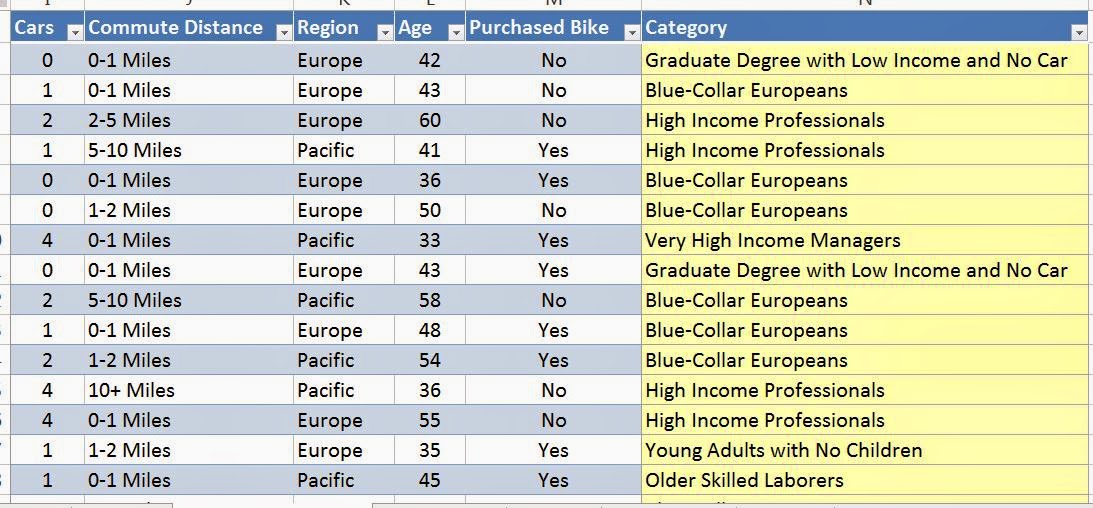
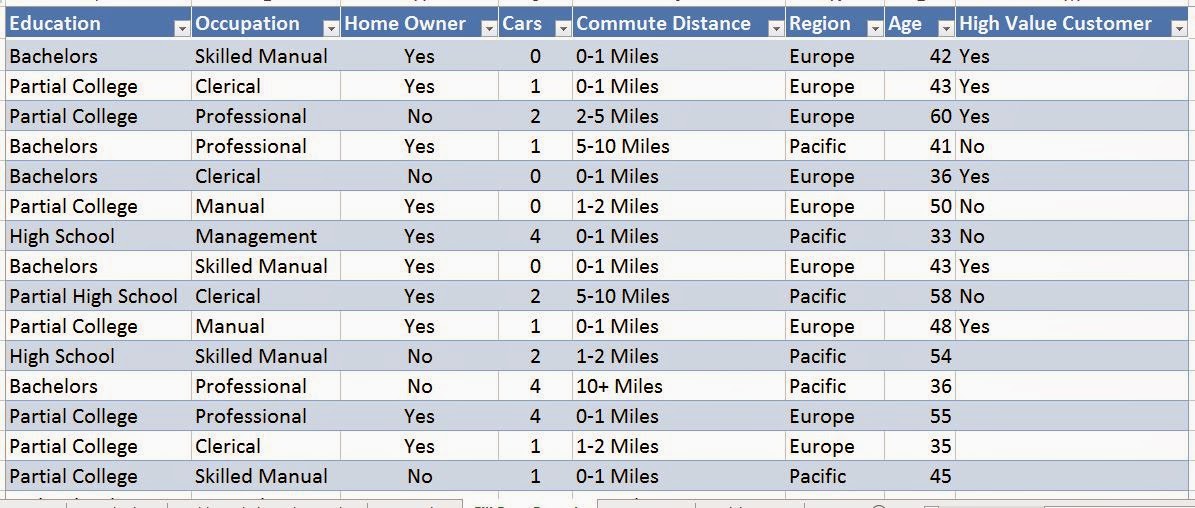
We have sales for three different regions, Europe, North America, and Pacific. We also have a date stamp of some type. When dealing with Year/Month values, we typically prefer to use Year + Month / 12 instead of YearMonth. However, the algorithm doesn't care very much. In fact, the time stamp seems to only be there for the user to see. The algorithm doesn't seem to use it at all. Let's get started.
 |
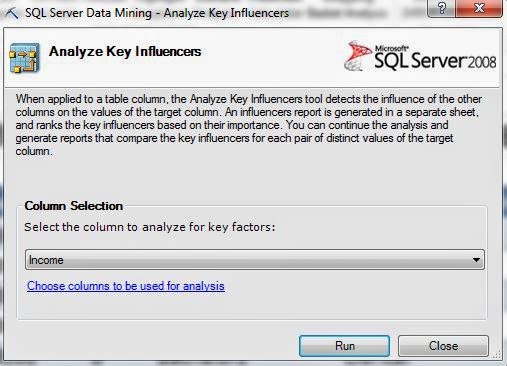
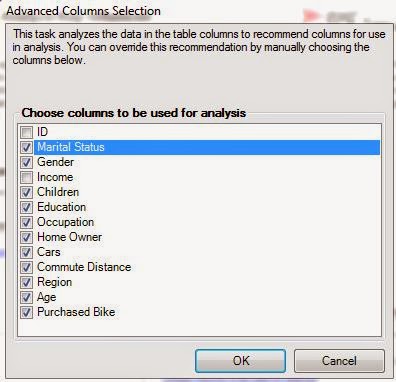
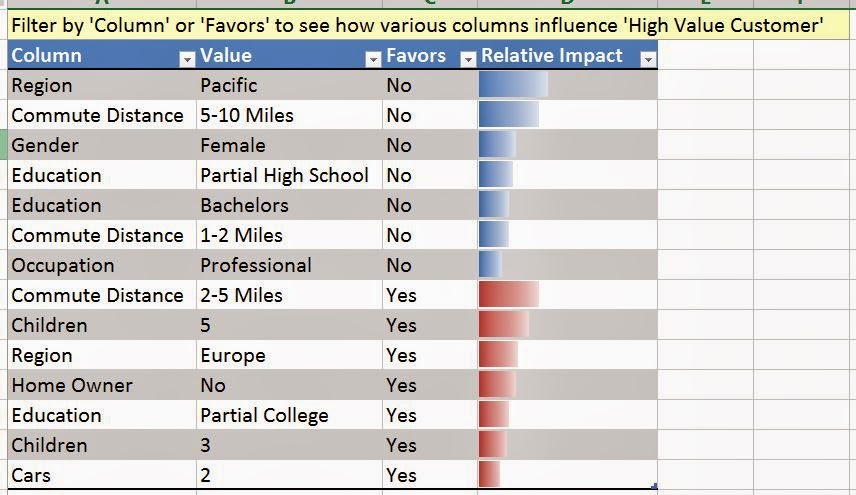
| Column Selection |
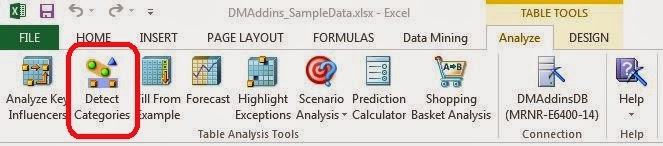
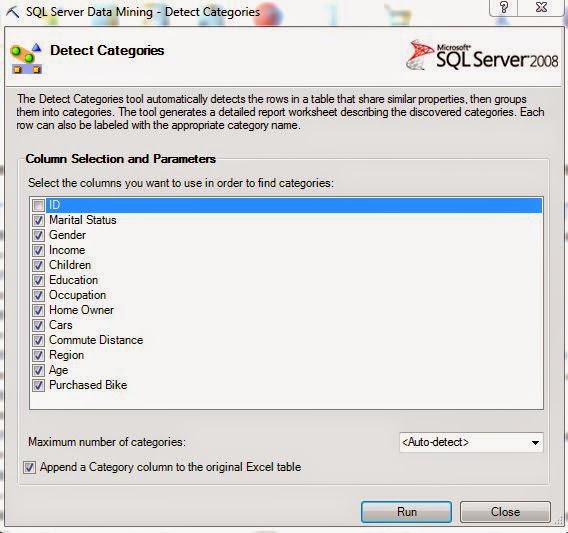
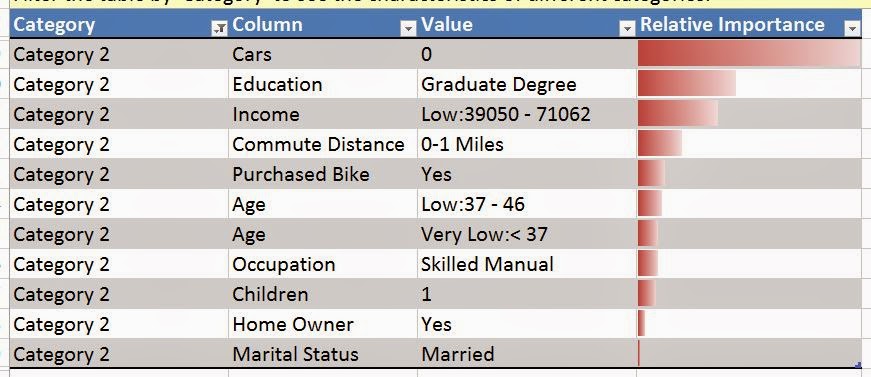
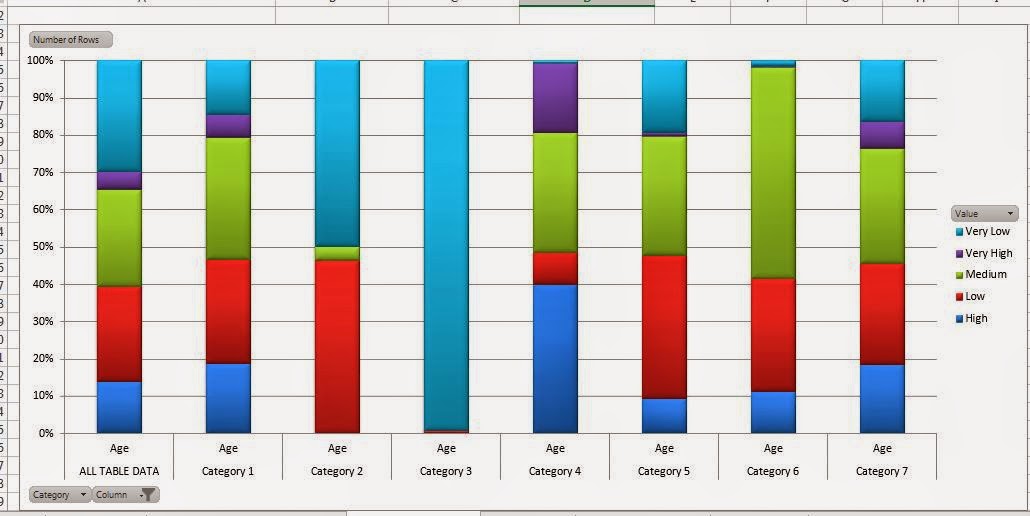
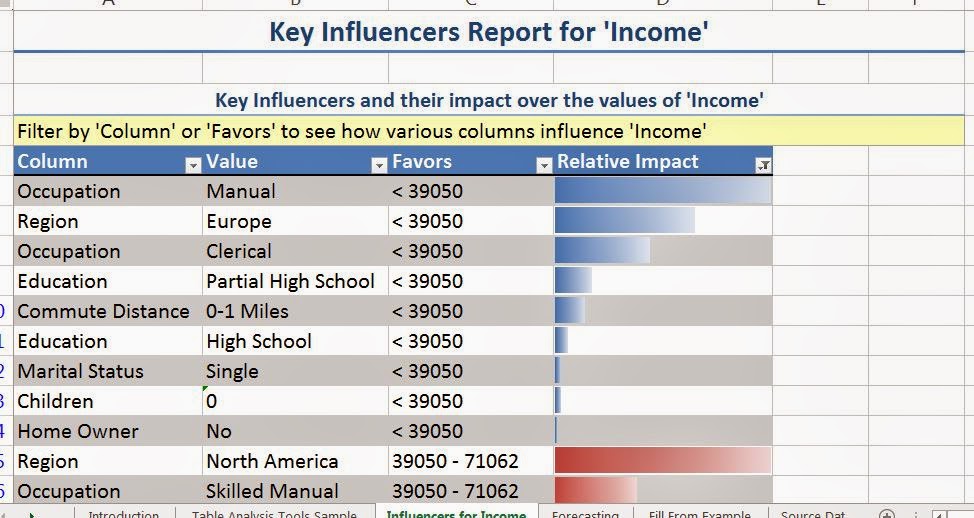
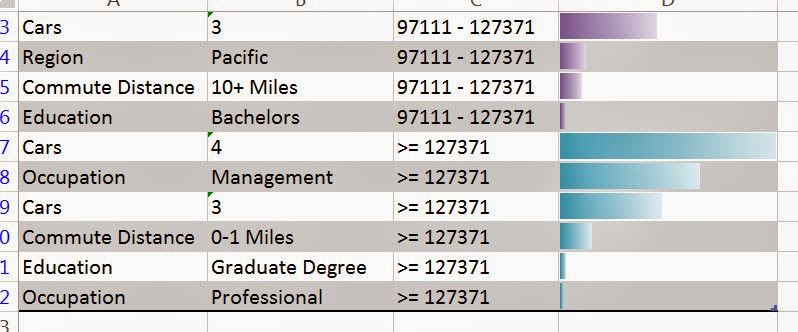
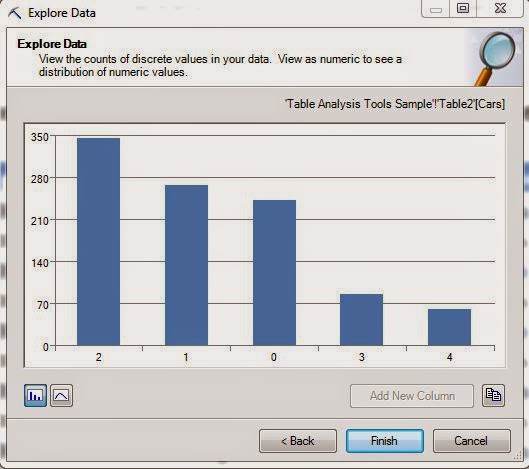
As usual, the algorithm lets us choose which columns we want to use. We can also tell the algorithm how many far into the future we want to forecast. Be careful how far you forecast into the future. The further ahead you look, the less accurate the prediction becomes. Also, the algorithm allows you to choose the periodicity of the data. For instance, if your data is monthly data, then you might have a yearly periodicity. This means that the data from this July is similar to the data from last July. However, the algorithm is pretty good at picking up on periodicity. Therefore, it's recommended that you use "Detect Automatically". Finally, you can tell the algorithm what to use as a time stamp. The algorithm doesn't actually use the time stamp, but it does make the resulting graph look much more intuitive. Now, let's see the output.
 |
| Forecast Chart |
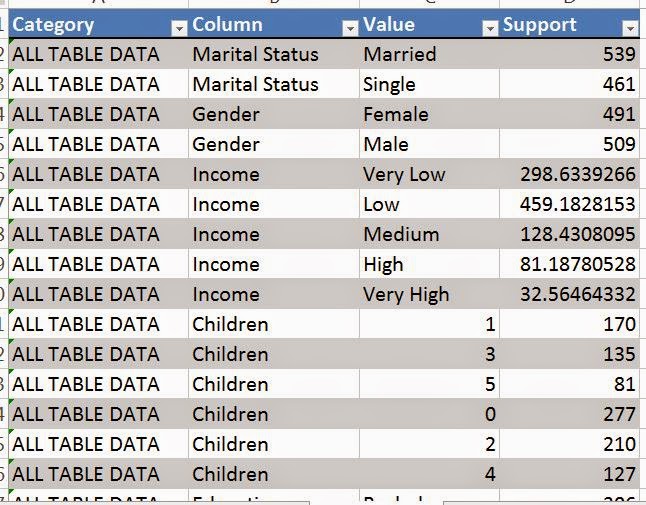
Voila! We now have forecasts for the next five months. As expected, the forecasted values have also been appended to the bottom of the original table.
 |
| Forecast Table |
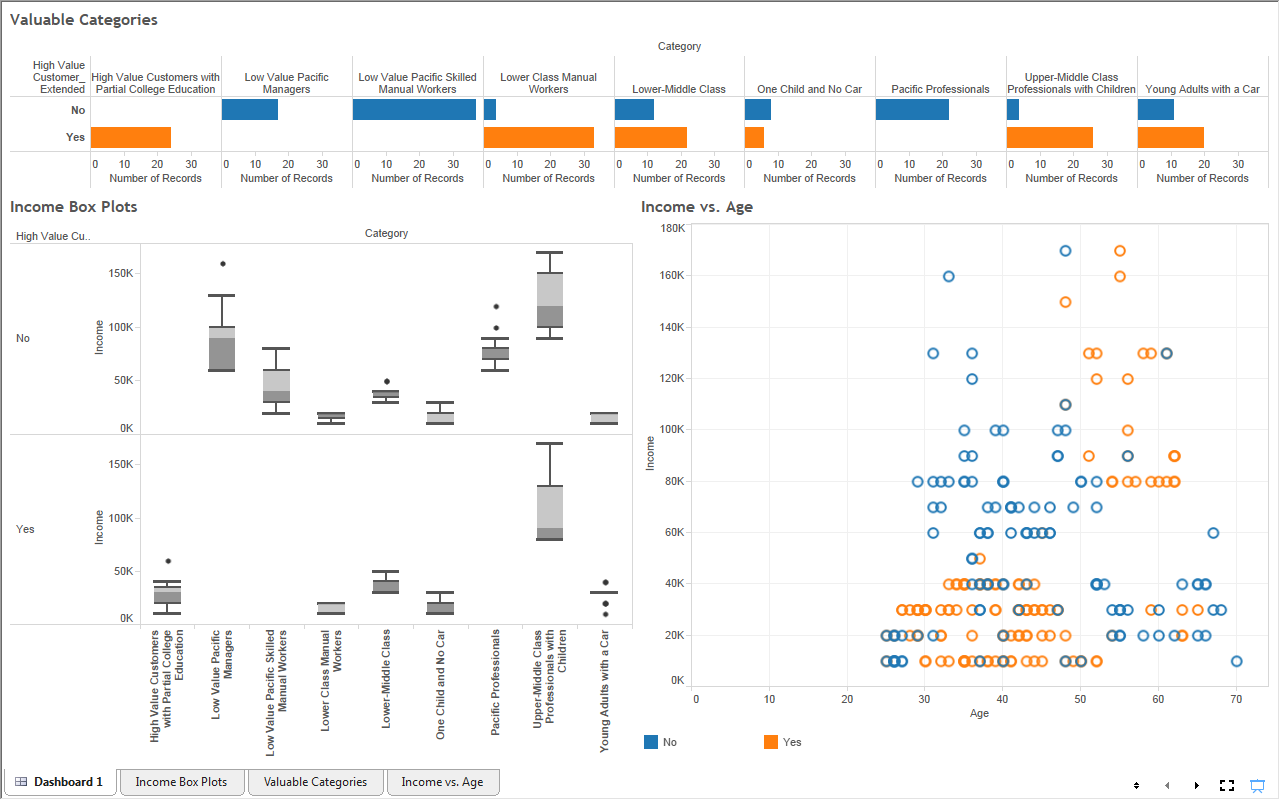
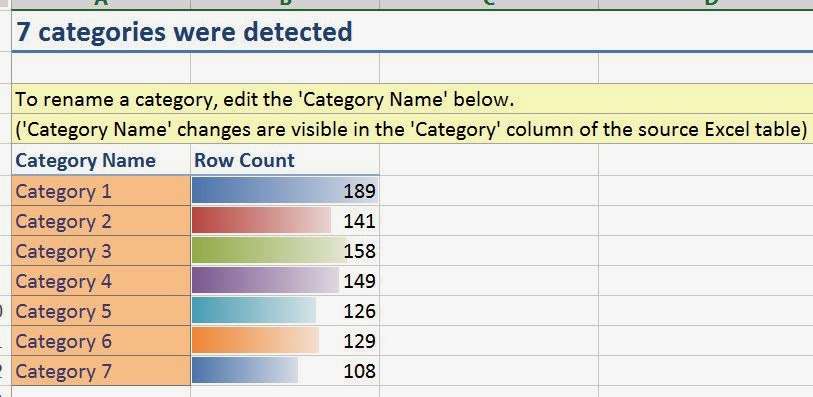
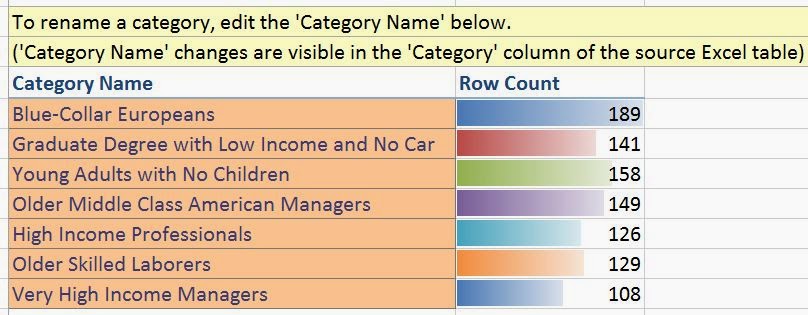
This is the point where we'd usually mock-up a simple dashboard showing you the amazing visuals you can see with the data. However, this data only contains Sales, Region, and MonthYear, which aren't the right types of variables variables to create any interesting visuals. However, there's nothing stopping you from combining the algorithms in you own data. For instance, you could use "Detect Categories" on your customers, then forecast the next six months of sales for each category. You could then use these forecasts to see which categories are likely to be profitable. Stay tuned for the next post where we'll be talking about Highlight Exceptions. Thanks for reading. We hope you found this informative.
Brad Llewellyn
Director, Consumer Sciences
Consumer Orbit
llewellyn.wb@gmail.com
Director, Consumer Sciences
Consumer Orbit
llewellyn.wb@gmail.com
http://www.linkedin.com/in/bradllewellyn
.JPG)