 |
| Experiment So Far |
 |
| Automobile Price Data (Clean) 1 |
 |
| Automobile Price Data (Clean) 2 |
 |
| Example Decision Tree |
In our example, we start with the entire dataset. Then, a single threshold is defined for a single variable that defines the "best" split. Next, the data is split across the two branches. On the false side, the algorithm decides that there's not enough data to branch again or the branch would not be "good" enough, so it ends in a leaf. This means that any records with a value of "Engine Size" > 182 will be assigned a "Predicted Price" of $6,888.41.
 |
| Example Decision Tree Predictions |
Now, we've talked about "Decision Tree Regression", but what's "Boosted Decision Tree Regression"? The process of "Boosting" involves creating multiple decision trees, where each decision tree depends on those that were created before it. For example, assume that we want to build 3 boosted decision trees. The first decision tree would attempt to predict the price for each record. The next tree would be calculated using the same algorithm, but instead of predicting price, it would try to predict the difference between the actual price and the price predicted by the previous tree. This is known as a residual because it is what's "left over" after the tree is built.. For example, if the first tree predicted a price of 10k, but the actual price was 12k, then the second tree would be trying to predict 12k - 10k = 2k instead of the original 12k. This way, when the algorithm is finished, the predicted price can be calculated simply by running the record through all of the trees, and adding all of the predictions. However, the process for building the individual trees is more complicated than this example would imply. You can read about it here and here. Let's take a look at the "Boosted Decision Tree Regression" module in Azure ML.
 |
| Boosted Decision Tree Regression |
The "Maximum Number of Leaves per Tree" parameter allows us to set the number of times the tree can split. It's important to note that splits early in the tree are caused by the most significant predictors, while splits later in the tree are less significant. This means that the more leaves we have (and therefore more splits), the higher our chance of Overfitting is. We'll talk more about this in a later post.
The "Minimum Number of Samples per Leaf Node" parameters allows us to set the significance level required for a split to occur. With this value set at 10, the algorithm will only choose to split (this is known as creating a "new rule") if at least 10 rows, or observations, will be affected. Increasing this value will lead to broad, stable predictions, while decreasing this value will lead to narrow, precise predictions.
The "Learning Rate" parameter allows us to set how much difference we see from tree to tree. MSDN describes this quite well as "the learning rate determines how fast or slow the learner converges on the optimal solution. If the step size is too big, you might overshoot the optimal solution. If the step size is too small, training takes longer to converge on the best solution."
The "Random Number Seed" parameter allows us to create reproducible results for presentation/demonstration purposes. Since this algorithm is not random, this parameter has no impact on this module.
Finally, we can choose to deselect "Allow Unknown Categorical Levels". When we train our model, we do so using a specific data set known as the training set. This allows the model to predict based on values it has seen before. For instance, our model has seen "Num of Doors" values of "two" and "four". So, what happens if we try to use the model to predict the price for a vehicle with a "Num of Doors" value of "three" or "five"? If we leave this option selected, then this new vehicle will have its "Num of Doors" value thrown into an "Unknown" category. This would mean that if we had a vehicle with three doors and another vehicle with five doors, they would both be thrown into the same "Num of Doors" category. To see exactly how this works, check out of our previous post, Regression Using Linear Regression (Ordinary Least Squares).
The options for the "Create Trainer Mode" parameter are "Single Parameter" and "Parameter Range". When we choose "Parameter Range", we instead supply a list of values for each parameter and the algorithm will build multiple models based on the lists. These multiple models must then be whittled down to a single model using the "Tune Model Hyperparameters" module. This can be really useful if we have a list of candidate models and want to be able to compare them quickly. However, we don't have a list of candidate models. Strangely, that actually makes "Tune Model Hyperparameters" more useful. We have no idea what the best set of parameters would be for this data. So, let's use it to choose our parameters for us.
 |
| Tune Model Hyperparameters |
 |
| Tune Model Hyperparameters (Visualization) |
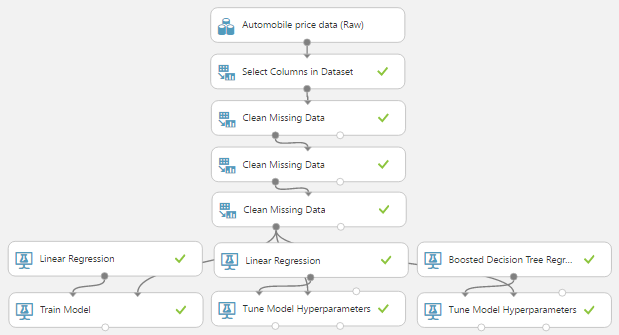 |
| OLS/OGD Linear Regression and Boosted Decision Tree Regression |
Brad Llewellyn
Data Scientist
Valorem
@BreakingBI
www.linkedin.com/in/bradllewellyn
llewellyn.wb@gmail.com
No comments:
Post a Comment