 |
| Experiment So Far |
 |
| Automobile Price Data (Clean) 1 |
 |
| Automobile Price Data (Clean) 2 |
So far in our experiment, we've trained our models using the entire data set. This is great because it gives the algorithm as much information as possible to make the best possible model. Now, let's think about how we would test the model. Testing the model, also known as model evaluation, requires that we determine how well the model would predict for data it hasn't seen yet. In practice, we could easily train the model using the entire dataset, then use that same dataset to test the model. However, that would determine how well the model can predict for data is has already seen, which is not the purpose of testing.
The most common approach to alleviate this issue is to split your data into two different sets, a Training Set and a Testing Set. The Training Set is used to train the model and the Testing Set is used to test the model. Using this methodology, we are testing the model with data it hasn't seen yet, which is the entire point. To do this, we'll use the "Split Data" module.
 |
| Split Data |
The "Fraction of Rows in the First Output Dataset" defines how many rows will be passed through the left output of the module. In our case, we'll use .7 (or 70%) of our data for our Training Set and the remaining 30% for our Testing Set. This is known as a 70/30 split and is generally considered the standard way to split.
The "Randomized Split" option is very important. If we were to deselect this option, the first segment of our rows (70% in this case) would go through the left output and the last segment (30% in this case) would go through the right side. Ordinarily, this is not what we would want. However, there may be some obscure cases where you could apply a special type of sorting beforehand, then use this technique to split the data. If you know of any other reasons, feel free to leave us a comment.
The "Random Seed" option allows us to split our data the same way every time. This is really helpful for demonstration and presentation purposes. Obviously, this parameter only matters if we have "Randomized Split" selected.
Finally, the "Stratified Split" option is actually quite significant. If we select "False" for this parameter, we will be performing a Simple Random Sample. This means that Azure ML will randomly choose a certain number of rows (70% in our case) with no regard for what values they have or what order they appeared in the original dataset. Using this method, it's possible (and actually quite common) for the resulting dataset to be biased in some way. Since the algorithm doesn't look at the data, it has no idea whether it's sampling too heavily from a particular category or not.
 |
| Price (Histogram) |
 |
| Split Data (Stratified) |
As an interesting side note, we experimented with this technique and found that creating Stratified Samples over Continuous variables (like price) can have interesting results. For instance, we built a dataset that contained a single column with the values 1 through 100 and no duplicates. When we tried to pull a 50% Stratified Sample of this data, we found that Azure ML takes a sample at every possible value. This means that it will try to take a 50% Simple Random Sample of a single row containing the value 5, for instance. In every case, taking a sample of a single row will guarantee that the row gets returned, regardless of the sampling percentage. Therefore, we ended up with all 100 rows in our left output and 0 rows in our right output, even though we wanted a 50/50 split.
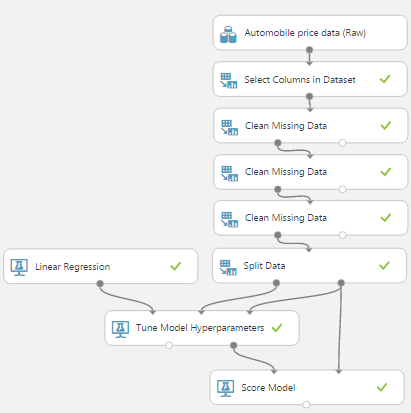
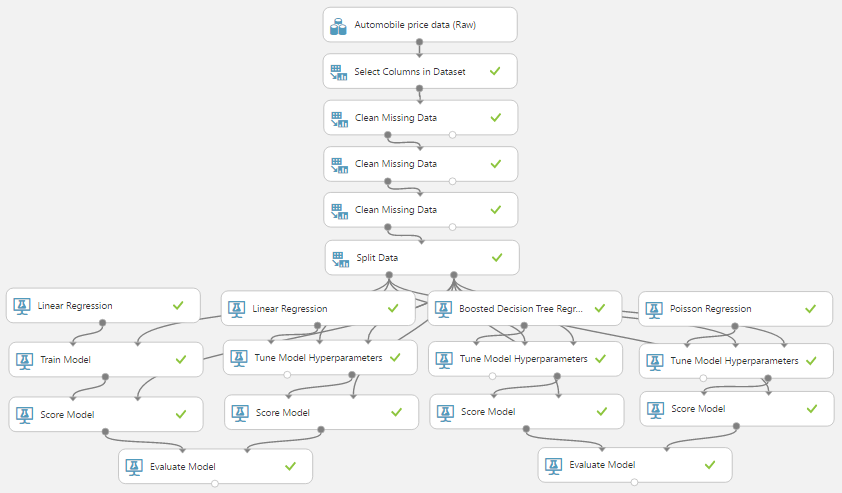
Now that we've created our 70/30 split of the data, let's look at how it fits into the experiment. We'll start by looking at the two different layouts, Train Model (which is used for Ordinary Least Squares Linear Regression) and Tune Model Hyperparameters (which is used for the other 3 regression algorithms).
 |
| Train Model |
 |
| Tune Model Hyperparameters |
 |
| Model Evaluation |
 |
| Ordinary Least Squares vs. Online Gradient Descent |
 |
| Boosted Decision Tree vs Poisson |
{kind=link}
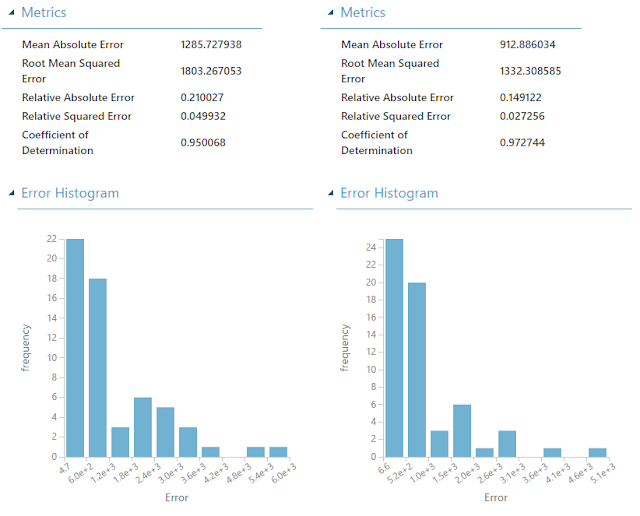
Some you may recognize that these visualizations look completely different than those created by the "Evaluate Model" module we used in our previous posts about ROC, Precision, Recall and Lift. This is because the model evaluation metrics for Regression are completely different than those for Classification. Looking at the Metrics section, we see that the first four metrics are Mean Absolute Error, Root Mean Squared Error, Relative Absolute Error and Relative Squared Error. All of these measures tell us how far our predictions deviate from the actual values they are supposed to predict. We don't generally pay much attention to these, but we do want to minimize these in practice.
The measure we are concerned with is Coefficient of Determination, also known as R Squared. We've mentioned this metric a number of times during this blog series, but never really described what it tells us. Basically, R Squared tells us how "good" our model is at predicting. Higher values of R Squared are good and smaller values are bad. It's difficult to determine what's an acceptable value. Some people say .7 and other people say .8. If we find anything lower than that, we might want to consider a different technique. Fortunately for us, the Poisson Regression model has an R Squared of .97, which is extremely good. As a side note, one of the reasons why we generally don't consider the values of the first four metrics is because they rarely differ from one another. If R Squared tells you that one model is the best, it's likely that all of the other metrics will tell you the same thing. R Squared simply has the advantage of being bounded between 0 and 1, which means we can identify not only which model is best, but also if that model is "good enough".
To finalize this evaluation, it seems that the Poisson Regression algorithm is the best model for this data. This is especially interesting because, in the previous post, we commented on the fact that the Poisson Distribution is not theoretically appropriate for this data. Given this, it may be a good idea to find an additional set of validation data to confirm our results. Alas, that's beyond the scope of this experiment.
Hopefully, this discussion has opened your horizons to the possibilities of using Regression to answer some more complex business problems. Stay tuned for the next post where we'll be talking about Normalizing Features for Regression. Thanks for reading. We hope you found this informative.
Brad Llewellyn
Data Scientist
Valorem
@BreakingBI
www.linkedin.com/in/bradllewellyn
llewellyn.wb@gmail.com
No comments:
Post a Comment