In the traditional data science space, feature selection is generally one of the first phases of a modelling process. A large reason for this is that, historically, building models using a hundred features would take a long time. Also, an individual would have to sort through all of the features after modeling to determine what impact the features were having. Sometimes, they would even find that some features would make the model less accurate by including them. There's also the concept of parsimony to consider. Basically, less variables was generally considered better.
However, technology and modelling techniques have come a long way over the last few decades. We would be doing a great disservice to modern Machine Learning to say that it resembles traditional statistics in a major way. Therefore, we try to approach feature selection from a more practical perspective.
First, we found that we were able to train over 1000 models in about an hour and a half. Therefore, removing features for performance reasons is not necessary. However, in other cases, it may be. In those cases, paring down features initially could be beneficial.
Now, we need to determine which variables are having no (or even negative) impact on the resulting model. If they aren't helping, then we should remove them. To do this, we can use a technique known as Permutation Feature Importance. Azure Machine Learning even has a built-in module for this. Let's take a look.
 |
| Feature Selection Experiment |
 |
| Permutation Feature Importance |
So, how does Permutation Feature Importance work? Honestly, it's one of more clever algorithms we've come across. The module chooses one feature at a time, randomly shuffles the values for that feature across the different rows, then retrains the model. Then, it can evaluate the impact of that feature by seeing how much the trained model changed when the values were shuffled. A very important feature would obviously cause large changes in the model if they were shuffled. A less important feature would have less impact. In our case, we want to measure impact by using Precision and Recall. Unfortunately, the module only gives us the option to use one at a time. Therefore, we'll have to be more creative. Let's start by looking at the output of the Precision module.
 |
| Feature Importance (Precision) 1 |
 |
| Feature Importance (Precision) 2 |
 |
| Feature Importance (Recall) 1 |
 |
| Feature Importance (Recall) 2 |
 |
| Feature Importance |
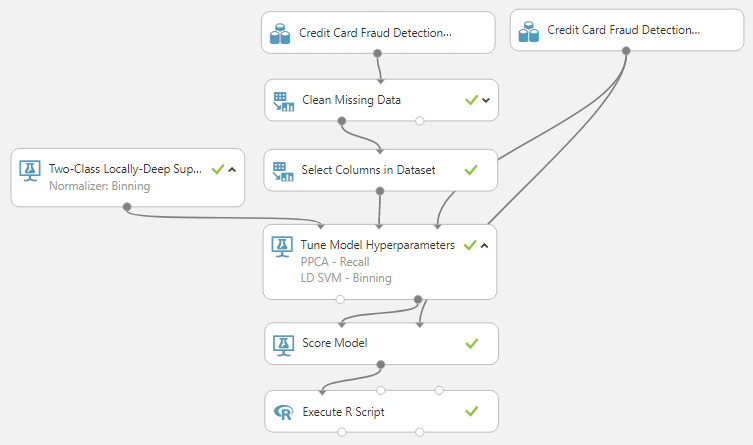 |
| Feature Reduction Experiment |
 |
| Tune Model Hyperparameters Results |
 |
| R Script Results |
It is important to note that in practice, we've never seen the "Permutation Feature Importance" model throw out the majority of the features. Usually, there are a few features that have a negative impact. As we slowly remove them one at a time, we eventually find that most of the features have a positive impact on the model. While we won't get into the math behind the scenes, we will say that we highly suspect this unusual case was caused by the fact that we are only given a subset of the Principal Components created using Principal Components Analysis.
Hopefully, this post enlightened you to some of the thought process behind Feature Selection in Azure Machine Learning. Permutation Feature Importance is a fast, simple way to improve the accuracy and performance of your model. Stay tuned for the next post where we'll be talking about Feature Engineering. Thanks for reading. We hope you found this informative.
Brad Llewellyn
Data Scientist
Valorem
@BreakingBI
www.linkedin.com/in/bradllewellyn
llewellyn.wb@gmail.com
No comments:
Post a Comment