 |
| Experiment So Far |
 |
| Automobile Price Data (Clean) 1 |
 |
| Automobile Price Data (Clean) 2 |
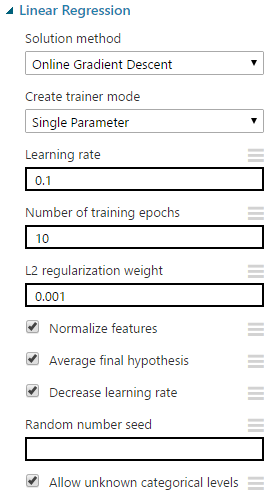 |
| Linear Regression (OGD) |
 |
| Gradient |
"Learning Rate" is also known as "Step Size". As the algorithm is trying to go downhill, it needs to know how far to move each time. This is what "Learning Rate" represents. A smaller step size would mean that we are more likely to find the bottom of the valley, but it also means that if we stuck in a valley that isn't the deepest, we may not be able to get out. Conversely, a larger step size would mean that we can more easily find the deepest valley, but may not be able to find the bottom of it. Fortunately, we can let Azure ML choose this value for us based on our data.
"Number of Training Epochs" defines how many times the algorithm will go through this learning process. Obviously, the larger the number of iterations, the longer the training process will take. Also, larger values could potentially lead to overfitting. As with the other parameters, we don't have to choose this ourselves.
Without going into too much depth, the "L2 Regularization Weight" parameter penalizes complex models in favor of simpler ones. Fortunately, there's a way that Azure ML will choose this value for us. So, we don't need to worry too much about it. If you want to learn more about Regularization, read this and this.
According to MSDN, "Normalize Features" allows us to "indicate that instances should be normalized". We're not quite sure what this is supposed to mean. There is a concept in regression of normalizing, also known as standardizing, the inputs. However, we did some testing and were not able to find a situation where this feature had any effect on the results. Please let us know in the comments if you know of one.
"Average Final Hypothesis" is much more complicated. Here's the description from MSDN:
In regression models, hypothesis testing means using some statistic to evaluate the probability of the null hypothesis, which states that there is no linear correlation between a dependent and independent variable.
In many regression problems, you must test a hypothesis involving more than one variable. This option, which is selected by default, tests a combination of the parameters where two or more parameters are involved.This seems to imply that utilizing the "Average Final Hypothesis" option takes into account the interactions between factors, instead of assuming they are independent. Interestingly, deselecting this option seems to generally produce better models. However, it also has an unwritten size limit. If we deselect this option and try to train the model using too many rows or columns, it will throw an error. Therefore, we can say that deselecting this option is extremely useful in some cases. We'll have to try it case-by-case to decide when it is appropriate and when it is not.
The "Decrease Learning Rate" option allows Azure ML to decrease the Learning Rate (aka Step Size) as the number of iterations increases. This allows us to hone in on an even better model by allowing us to find the tip of the valley. However, reducing the learning rate also increases the chances that we get stuck in a local minima (one of the shallow valleys). Deselecting this option is susceptible to the same size limitation as "Average Final Hypothesis", but doesn't seem to have the same positive impact. Unless we can find a good reason, let's leave this option selected for the time being.
Choosing a value for "Random Number Seed" defines our starting point and allows us to create reproducible results in case we need to use them for demonstrations or presentations. If we don't provided a value for this parameter, one will be randomly generated.
Finally, we can choose to deselect "Allow Unknown Categorical Levels". When we train our model, we do so using a specific data set known as the training set. This allows the model to predict based on values it has seen before. For instance, our model has seen "Num of Doors" values of "two" and "four". So, what happens if we try to use the model to predict the price for a vehicle with a "Num of Doors" value of "three" or "five"? If we leave this option selected, then this new vehicle will have its "Num of Doors" value thrown into an "Unknown" category. This would mean that if we had a vehicle with three doors and another vehicle with five doors, they would both be thrown into the same "Num of Doors" category. To see an example of this, read our previous post.
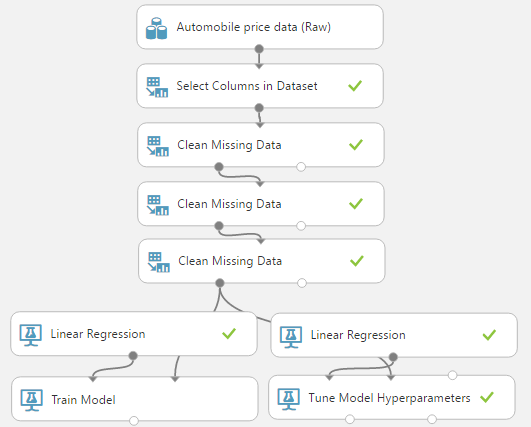
Now that we've walked through all of the parameters, we can use the "Tune Model Hyperparameters" module to choose them for us. However, it will only choose values for "Learning Rate", "Number of Epochs" and "L2 Regularization Weight". Since we also found that "Average Final Hypothesis" was significant, we should create two separate streams, one with this option selected and one without. For an explanation of how "Tune Model Hyperparameters" works, read one our previous posts.
 |
| Tune Model Hyperparameters |
 |
| Tune Model Hyperparameters (Visualization) (Average Final Hypothesis) |
 |
| Tune Model Hyperparameters (Visualization) (No Average Final Hypothesis) |
Also, it's important to note that the best model with "Average Final Hypothesis" has an R squared of .678 compared to an R squared of .769 without. This is what we meant when we said that disabling the option seems to produce better results. Unfortunately, our lack of familiarity with what the parameter actually does means that we're not sure if this result is valid or not. The best we can do is assume that it is. If you have any information on this, please let us know.
 |
| OLS and OGD Linear Regression |
Brad Llewellyn
Data Scientist
Valorem
@BreakingBI
www.linkedin.com/in/bradllewellyn
llewellyn.wb@gmail.com
No comments:
Post a Comment