Today, we're going to talk about HDInsight Hive within Power BI. If you haven't read the earlier posts in this series,
Introduction,
Getting Started with R Scripts,
Clustering,
Time Series Decomposition,
Forecasting,
Correlations,
Custom R Visuals,
R Scripts in Query Editor,
Python,
Azure Machine Learning Studio,
Stream Analytics and
Stream Analytics with Azure Machine Learning Studio, they may provide some useful context. You can find the files from this post in our
GitHub Repository. Let's move on to the core of this post, HDInsight Hive.
HDInsight is a managed Hadoop platform available on Azure. On the back-end, HDInsight is enabled by a partnership between Hortonworks and Microsoft to bring the
Hortonworks Data Platform (HDP) to Azure as a Platform-as-a-Service option. This allow us to leverage much of the functionality of the Hadoop ecosystem, without having to manage and provision the individual components. HDInsight comes in a number of configurations for different needs, such as Kafka for Real-Time Message Ingestion, Spark for Batch Processing and ML Services for Scalable Machine Learning. Although most of the HDInsight configurations include Hive, we'll be using the Interactive Query configuration. You can read more about HDInsight
here.
Hive is a "SQL on Hadoop" technology that combines the scalable processing framework of the ecosystem with the coding simplicity of SQL. Hive is very useful for performant batch processing on relational data, as it leverages all of the skills that most organizations already possess. Hive LLAP (Low Latency Analytical Processing or Live Long and Process) is an extension of Hive that is designed to handle low latency queries over massive amounts of
EXTERNAL data. One of this coolest things about the Hadoop SQL ecosystem is that the technologies allow us to create SQL tables directly on top of structured and semi-structured data without having to import it into a proprietary format. That's exactly what we're going to do in this post. You can read more about Hive
here and
here and Hive LLAP
here.
We understand that SQL queries don't typically constitute traditional data science functionality. However, the Hadoop ecosystem has a number of unique and interesting data science features that we can explore. Hive happens to be one of the best starting points on that journey.
Let's start by creating an HDInsight cluster in the Azure portal.
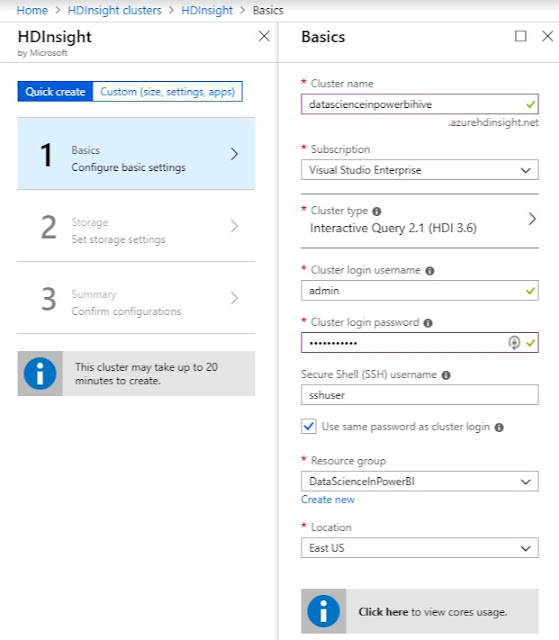 |
| HDInsight Creation Basics |
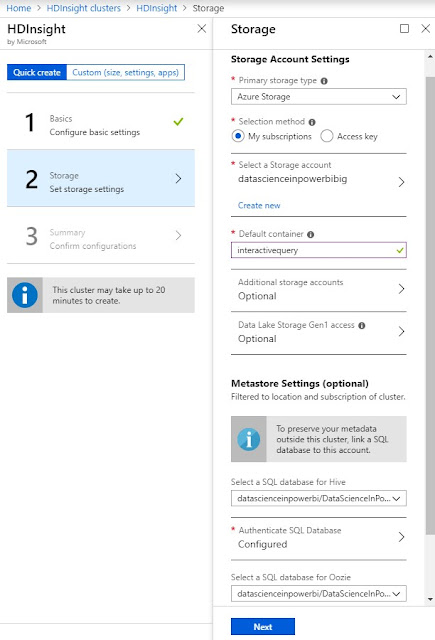 |
| HDInsight Creation Storage |
 |
| HDInsight Creation Cluster Size |
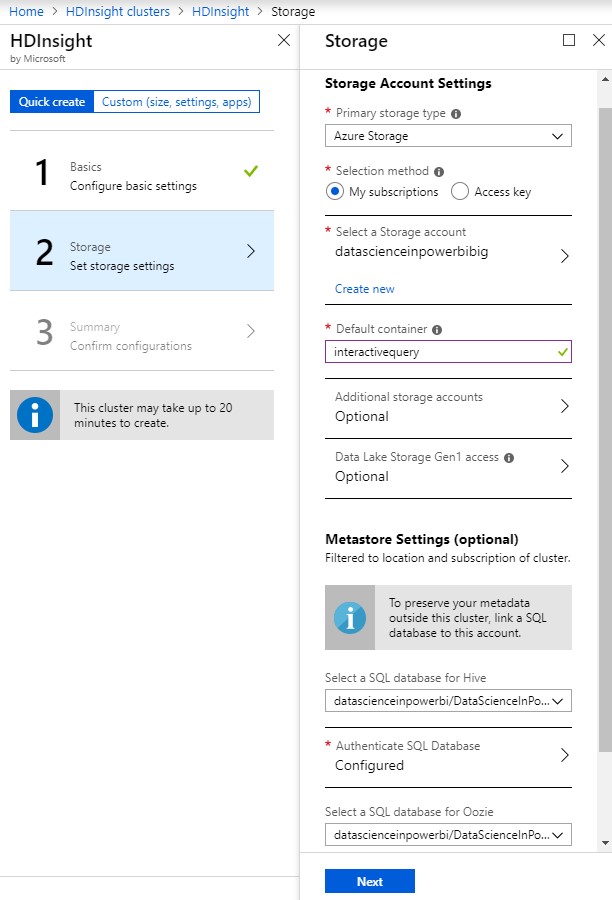
When we provisioned the cluster, we connected it to an Azure Storage account named "datascienceinpowerbibig". This is important because HDInsight clusters have two types of storage available, internal and external. Internal storage is provisioned with the cluster and is deleted when it is deprovisioned. External storage is provisioned separately and remains after the cluster is deprovisioned. Additionally, the external storage is easily accessible by other Azure resources. It's also important to note that we opened up the advanced options and reduced the cluster size as small as possible. Even then, this cluster costs $2.75 per hour, which adds up to $2,046 per month. This pricetag is why many organizations provision HDInsight clusters only when they need them, then deprovision them when they are done.
Now that our cluster is provisioned, let's take a look at the Blob store where we pointed our cluster.
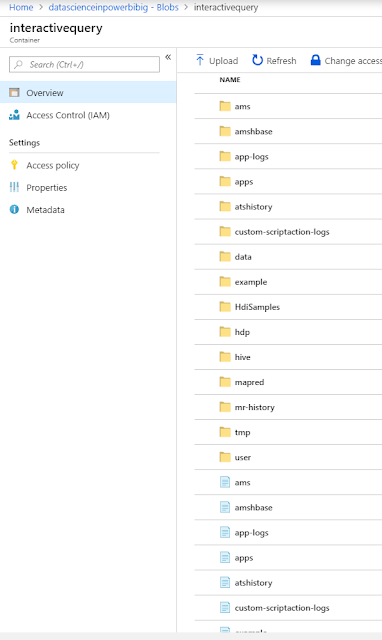 |
| HDInsight Storage |
We see that the HDInsight cluster has created a number of directories that it uses to store its data and metadata. In addition to the automatically created files, we added a "data" directory and added a bunch of data files to it.
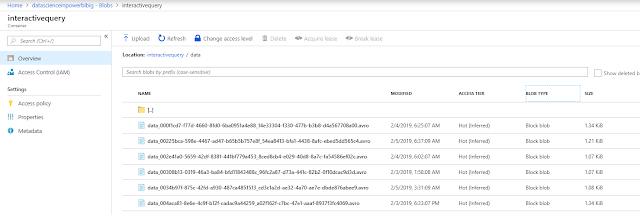 |
| HDInsight Data |
It's important to note that these files are all very small. Hive is known to perform better on a small number of large files than it does on a large number of small files. So, the data we have here is not optimal for querying. Perhaps this is a good topic for a later post (WINK, WINK). It's also important to note that these files are stored in Avro format. Avro is one of the recommended formats for storing data that is to be queried by Hive. You can read more about Avro
here and Hive Data Formats
here.
Now that we've seen our raw data, let's navigate to the SQL Interface within HDInsight.
 |
| Ambari |
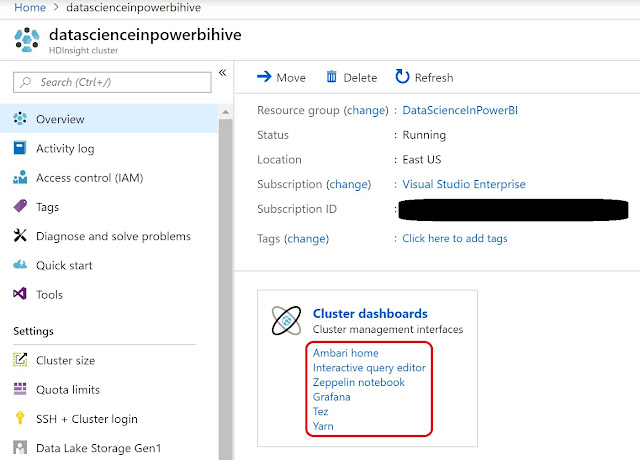
Many of the administrative interfaces and dashboards can be found within Ambari, which can be accessed from the HDInsight resource blade in the Azure portal.
 |
| Hive View |
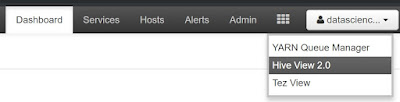
In Ambari, we can access the "Hive View 2.0" by clicking the waffle in the top-right corner of the window.
 |
| Blank Query |
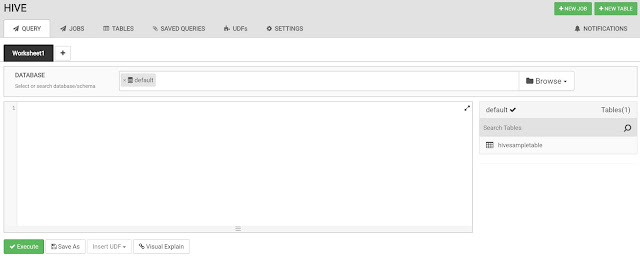
The Hive View takes us to a blank query window. This is where we could write our queries. For now, we're more interested in creating a table. We could do this with SQL commands, but the Hive View has a nice GUI for us to use as well.
 |
| New Table |
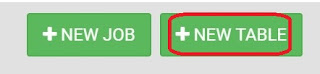
We can access this GUI by clicking the "+New Table" button in the top-right corner of the window.
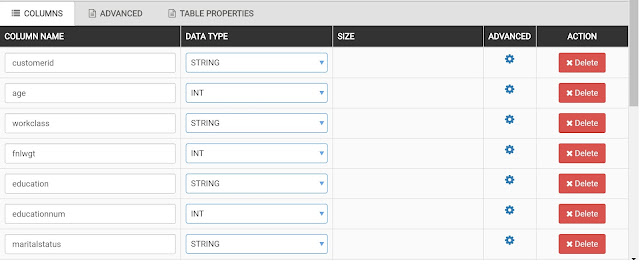 |
| Columns |
We start by defining all of the columns in our dataset.
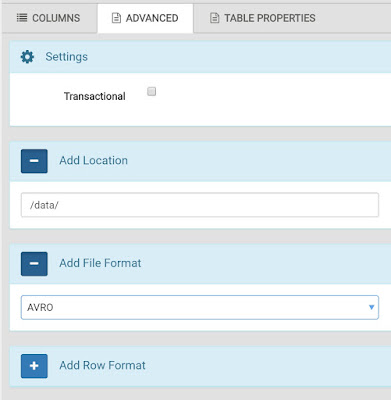 |
| Advanced |
Then, we can go to the Advanced tab to supply the location of the data and the file formats. Since our HDInsight cluster is directly connected to the Azure Storage Account, we don't have to worry about defining complex path names. The cluster can access the data simply by using the relative path name of "/data/".
Now that we've created our table, we can go back to the Query editor and query it.
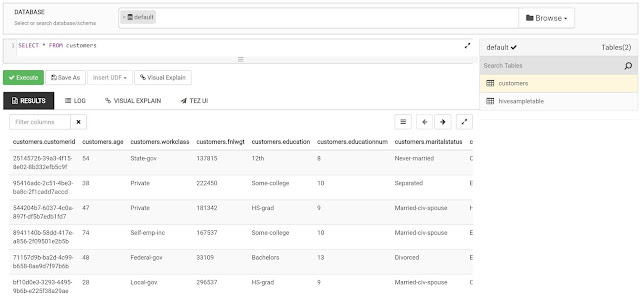 |
| Customers |
We also have the ability to see the code that was generated to create the table by navigating to the Tables tab.
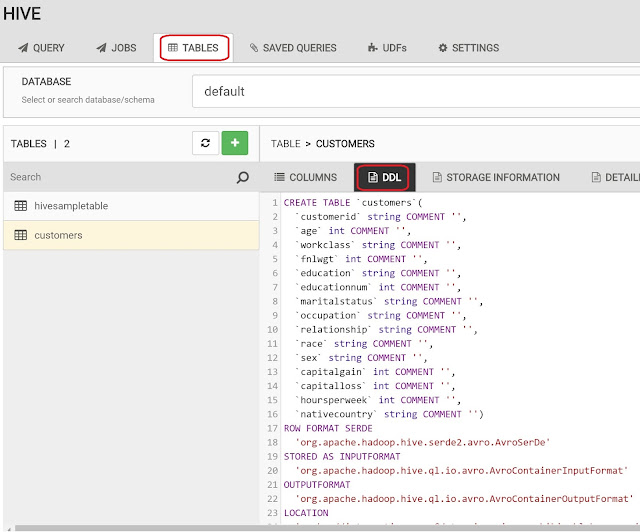 |
| DDL |
Now that we've taken a look at our table, let's get to the Power BI portion. One of the really cool things about Hive is that it exposes our data using the same SQL drivers that we are used to. This means that most tools can easily access it, including Power BI.
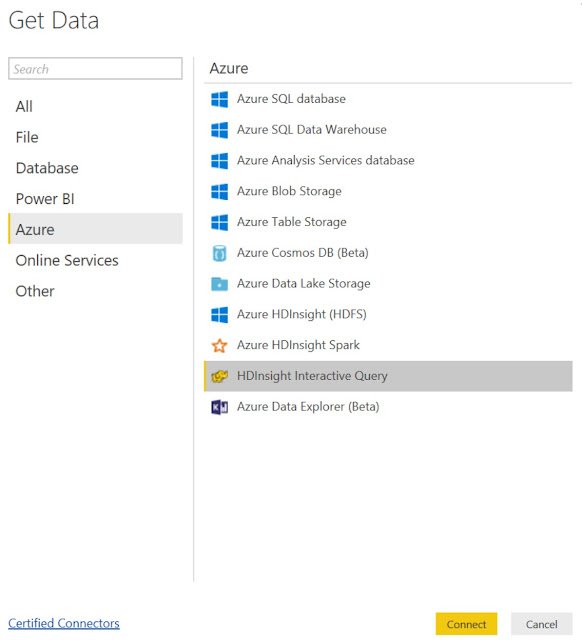 |
| Get Data |
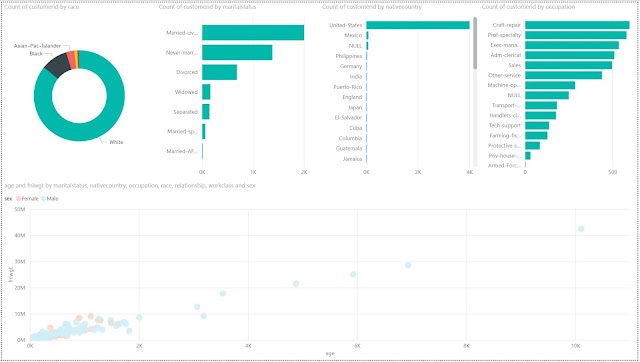 |
| Power BI Report |
Once we connect to the table, we can use the same Power BI functionality as always to create our data visualizations. It's important to note that there are substantial performance implications of using "DirectQuery" mode to connect to Hive LLAP clusters. Hive LLAP is optimized for this type of access, but it's not without complexity. Many organizations that leverage this type of technology put a substantial amount of effort into keeping the database optimized for read performance.
Hopefully, this post opened your eyes a little to the power of leveraging Big Data within Power BI. The potential of SQL and Big Data is immense and there are many untapped opportunities to leverage it in our organizations. Stay tuned for the next post where we'll be looking into Databricks Spark. Thanks for reading. We hope you found this informative.
Brad Llewellyn
Service Engineer - FastTrack for Azure
Microsoft
@BreakingBI
www.linkedin.com/in/bradllewellyn
llewellyn.wb@gmail.com













No comments:
Post a Comment