Today, we're going to talk about Cluster Creation in Azure Databricks. If you haven't read the first post in this series,
Introduction, it may provide some useful context. You can find the files from this post in our
GitHub Repository. Let's move on to the core of this post, Cluster Creation.
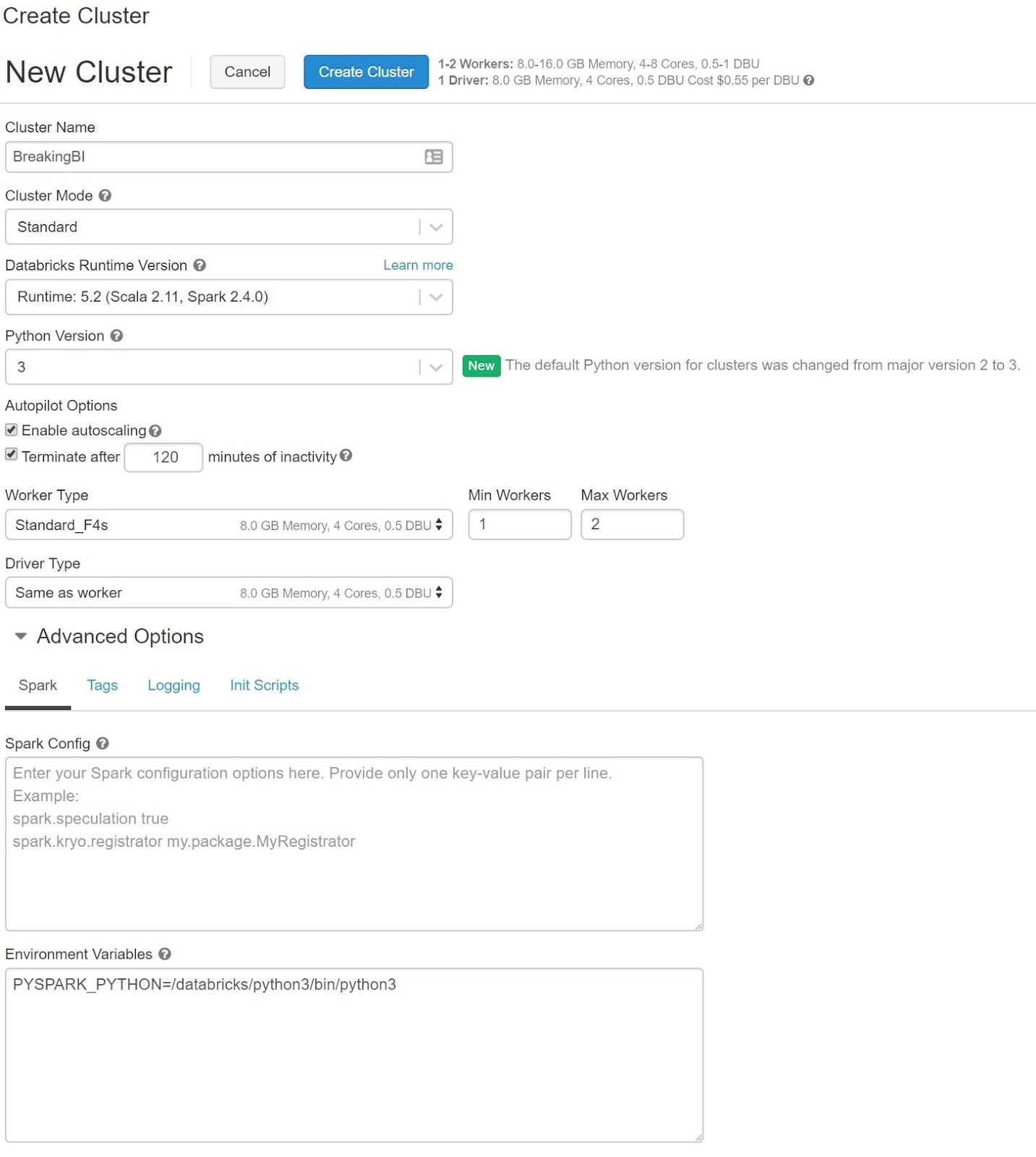
There are three major concepts for us to understand about Azure Databricks, Clusters, Code and Data. We will dig into each of these in due time. For this post, we're going to talk about Clusters. Clusters are where the work is done. Clusters themselves do not store any code or data. Instead, they operate the physical resources that are used to perform the computations. So, it's possible (and even advised) to develop code against small development clusters, then leverage the same code against larger production-grade clusters for deployment. Let's start by creating a small cluster.
 |
| New Cluster |
 |
| Cluster Properties |
Let's dig into this.
 |
| Cluster Mode |
First, we're setting up this cluster in "Standard" mode. This is the typical cluster mode that is very useful for developing code, performing analyses or running individual jobs. The other option is "High Concurrency". This mode is optimized for multiple users running multiple jobs at the same time. You can read more about Cluster Modes
here.
 |
| Python Version |
Then, we have to decide whether we want to use Python 2 or Python 3. Long story short, Python 2 and Python 3 are very different languages. Python 3 is the newest version and should be used in the majority of cases. In rare cases where we are trying to productionalize existing Python 2 code, then Python 2 can be leveraged. You can read more about Python Versions
here.
 |
| Autopilot Options |
Two of the major selling points of Databricks are listed under the "Autopilot Options" section. First, Databricks clusters have the ability to monitor performance stats and autoscale the cluster based on those stats. This level of elasticity is virtually unheard of in most other Hadoop products. You can read more about autoscaling
here.
Additionally, we have the ability to automatically stop, but not delete, clusters that are no longer being used. Anyone who's ever worked with a product that requires people to manually spin up and spin down resources can attest that it is extremely common for people to forget to turn them off after their done. This autotermination, along with the autoscaling mentioned previously, leads to a substantial cost savings. You can read more about autotermination
here.
 |
| Worker Type |
Databricks also gives us the ability to decide what size of cluster we want to create. As we mentioned previously, this flexibility is an efficient way to limit costs while developing by leveraging less expensive clusters. For more advanced users, there are also a number different cluster types optimized for different performance profiles, including high CPU, high Memory, high I/O or GPU-acceleration. You can read more about Worker Types
here.
 |
| Min and Max Workers |
With autoscaling enabled, we also have the ability to define how large or small the cluster can get. This is an effective technique for guaranteeing thresholds for performance and price. You can find out more about autoscaling
here.
 |
| Driver Type |
We also have the ability to use a different driver type than we use for the workers. The worker nodes are used to perform the computations needed for any notebooks or jobs. The driver nodes are used to store metadata and context for Notebooks. For example, a notebook that processes a very complex dataset, but doesn't output anything to the user will require larger worker nodes. On the other hand, a notebook that processes a very simple dataset, but outputs a lot of data to the user for manipulation in the notebook will require larger driver nodes. Obviously this setting is designed for more advanced users. You can read more about Cluster Node Types
here.
With all of these cluster configuration options, it's obvious there are many ways to limit the overall price of our Azure Databricks environment. This is a level of flexibility not present in any other major Hadoop environment, and one of the reasons why Databricks has gained so much popularity. Let's move on to the advanced options at the bottom of this screen.
 |
| Advanced Options - Spark |
Behind every Spark cluster, there are a large number of configuration options. Azure Databricks uses many of the common default values. However, there are some cases where advanced users may want to change some of these configuration values to improve performance or enable more complex features. You can read more about Apache Spark configuration options
here.
In addition, we can create environment variables that can then be used as part of scripts and code. This is especially helpful when we want to run complex scripts or create reusable code that can be ported from cluster to cluster. For instance, we can easily transition from Dev to QA to Prod clusters by storing the connection string for the associated database as an environment variable. Slightly off-topic, there's also a secure way to handle this using
secrets or
Azure Key Vault. You can read more about the Spark Advanced options
here.
 |
| Advanced Options - Tags |
Tags are actually an Azure feature that is unrelated to Azure Databricks. Tags allow us to create
key-value pairs that can be used to filter or group our Azure costs. This is a great way to keep track of how many particular projects, individuals or cost centers are spending in Azure. Tags also provide some advantages for Azure administration, such as understanding what resources belong to which teams or applications. You can read more about Tags
here.
 |
| Advanced Options - Logging |
We also have the option to decide where our driver and worker log files will be sent. Currently, it appears the only supported destination is DBFS, which we haven't talked about yet. However, it is possible to
mount an external storage location to DBFS, thereby allowing us to write these log files to an external storage location. You can read more about Logging
here.
 |
| Advanced Options - Init Scripts |
We have the ability to run initialization scripts during the cluster creation process. These scripts are run before the Spark driver or Worker JVM starts. Obviously, this is only for very advanced users who need specific functionality from their clusters. It's interesting to note that these scripts only have access to set of pre-defined environment variables and do not have access to the user-defined environment variables that we looked at previously. You can read more about Initialization Scripts
here.
 |
| Advanced Options - ADLS Gen1 |
If we select "High Concurrency" as our Cluster Type, we also have an additional option to pass through our credentials to Azure Data Lake Store Gen1. This means that we don't have worry about configuring access using secrets or configurations. However, this does limit us to only using only SQL and Python commands. You can read more about ADLS Gen1 Credential Passthrough
here.
That's all there is to creating clusters in Azure Databricks. We love the fact that Azure Databricks makes is incredibly easy to spin up a basic cluster, complete with all the standard libraries and packages, but also gives us the flexibility to create more complex clusters as our use cases dictate. Stay tuned for the next post where we'll dig into Notebooks. Thanks for reading. We hope you found this informative.
Brad Llewellyn
Service Engineer - FastTrack for Azure
Microsoft
@BreakingBI
www.linkedin.com/in/bradllewellyn
llewellyn.wb@gmail.com












No comments:
Post a Comment