Azure Machine Learning Studio is a tool that we have talked about extensively on this blog. It allows us to create advanced analytic and predictive modeling experiments using an intuitive, drag-and-drop interface. It also allows us to easily productionalize our predictive models by using Azure Machine Learning Studio APIs. Here are links to the first posts in two different series that cover these topics, Azure Machine Learning: Getting Started and Azure Machine Learning in Practice: Fraud Detection.
In this post, we're going to use an Azure Machine Learning Studio dataset that we've seen in a number of posts, as well as our presentations, Azure Machine Learning Studio: Making Data Science Easy(er) and Azure Machine Learning Studio: Four Tips from the Pros. This is the Adult Census Income Binary Classification Dataset. Our goal will be to predict the customer's income based on a number of demographic features.
Since we're going to be using this dataset in Azure Machine Learning Studio and Power BI, the easiest option is to put it in an Azure SQL Database and let both of them query it from there. Before we do that, we want to split the data into two different sets, a training set for building the model and a testing set for testing the results. We've talked about this technique a number of times on this blog. Here's one example. Fortunately, this is quite easy to do in Azure Machine Learning Studio using the "Split Data" module.
 |
| Create Testing and Training Sets |
<CODE START>
CREATE TABLE Customers (
age INT
,workclass NVARCHAR(255)
,fnlwgt INT
,education NVARCHAR(255)
,[education-num] INT
,[marital-status] NVARCHAR(255)
,occupation NVARCHAR(255)
,relationship NVARCHAR(255)
,race NVARCHAR(255)
,sex NVARCHAR(255)
,[capital-gain] INT
,[capital-loss] INT
,[hours-per-week] INT
,[native-country] NVARCHAR(255)
,income NVARCHAR(255)
)
CREATE TABLE Customers_New (
age INT
,workclass NVARCHAR(255)
,fnlwgt INT
,education NVARCHAR(255)
,[education-num] INT
,[marital-status] NVARCHAR(255)
,occupation NVARCHAR(255)
,relationship NVARCHAR(255)
,race NVARCHAR(255)
,sex NVARCHAR(255)
,[capital-gain] INT
,[capital-loss] INT
,[hours-per-week] INT
,[native-country] NVARCHAR(255)
,income NVARCHAR(255)
)
<CODE END>
After loading the data to the tables, we confirm the data's there and can move on to creating the predictive model.
 |
| Check Record Counts |
 |
| Create Predictive Model |
 |
| Evaluation Results |
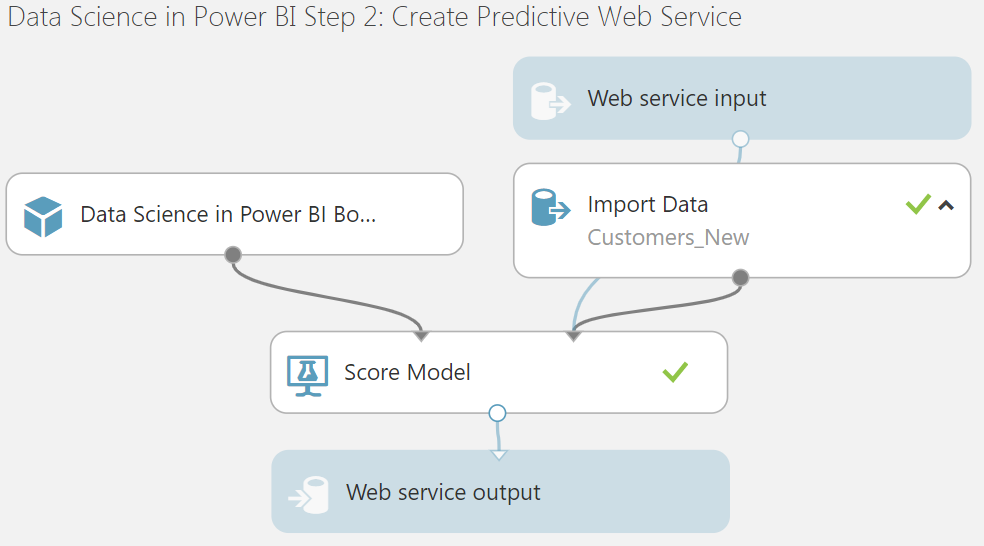 |
| Create Predictive Web Service |
 |
| Web Service Deployed |
{kind=link}
Now that we have the web service deployed to Azure, we need to be able to call this from Power BI. To do this, we could use either R or Python. Since Python is still in preview at the time of writing, we'll use R. Fortunately, the Azure Machine Learning Web Services portal provides the code for us. All we have to do is navigate to the "Consume" tab and select "Request-Response -> R".
| Consume |
 |
| Request-Response R Code |
{kind=link}
Here's the code that it provides.
<CODE START>
library("RCurl")
library("rjson")
# Accept SSL certificates issued by public Certificate Authorities
options(RCurlOptions = list(cainfo = system.file("CurlSSL", "cacert.pem", package = "RCurl")))
h = basicTextGatherer()
hdr = basicHeaderGatherer()
req = list(
Inputs = list(
"input1"= list(
list(
'id' = "1",
'age' = "1",
'workclass' = "",
'fnlwgt' = "1",
'education' = "",
'education-num' = "1",
'marital-status' = "",
'occupation' = "",
'relationship' = "",
'race' = "",
'sex' = "",
'capital-gain' = "1",
'capital-loss' = "1",
'hours-per-week' = "1",
'native-country' = "",
'income' = ""
)
)
),
GlobalParameters = setNames(fromJSON('{}'), character(0))
)
body = enc2utf8(toJSON(req))
api_key = "abc123" # Replace this with the API key for the web service
authz_hdr = paste('Bearer', api_key, sep=' ')
h$reset()
curlPerform(url = "https://ussouthcentral.services.azureml.net/subscriptions/143cebb47ba243ec9422da9787ff546b/services/2be5b160bdca49e4aa580f21795ff1e5/execute?api-version=2.0&format=swagger",
httpheader=c('Content-Type' = "application/json", 'Authorization' = authz_hdr),
postfields=body,
writefunction = h$update,
headerfunction = hdr$update,
verbose = TRUE
)
headers = hdr$value()
httpStatus = headers["status"]
if (httpStatus >= 400)
{
print(paste("The request failed with status code:", httpStatus, sep=" "))
# Print the headers - they include the requert ID and the timestamp, which are useful for debugging the failure
print(headers)
}
print("Result:")
result = h$value()
print(fromJSON(result))
<CODE END>
Since this code uses a hard-coded list of 1's and empty strings. We can directly test this in RStudio without needing to use it in Power BI yet. In order to use this code, we need to install the "RCurl" and "rjson" packages. RCurl allows us to execute HTTP Requests against web service endpoints, while rjson allows us to create and parse the json payloads used by the web service. We also need to provide our API Key on the following line:
api_key = "abc123" # Replace this with the API key for the web service
The API Key can be found on the "Consume" tab of the Azure Machine Learning Web Services Portal.
The final output from the R code is as follows:
<OUTPUT START>
$Results
$Results$output1
$Results$output1[[1]]
$Results$output1[[1]]$id
[1] "1"
$Results$output1[[1]]$age
[1] "1"
$Results$output1[[1]]$workclass
NULL
$Results$output1[[1]]$fnlwgt
[1] "1"
$Results$output1[[1]]$education
NULL
$Results$output1[[1]]$`education-num`
[1] "1"
$Results$output1[[1]]$`marital-status`
NULL
$Results$output1[[1]]$occupation
NULL
$Results$output1[[1]]$relationship
NULL
$Results$output1[[1]]$race
NULL
$Results$output1[[1]]$sex
NULL
$Results$output1[[1]]$`capital-gain`
[1] "1"
$Results$output1[[1]]$`capital-loss`
[1] "1"
$Results$output1[[1]]$`hours-per-week`
[1] "1"
$Results$output1[[1]]$`native-country`
NULL
$Results$output1[[1]]$income
NULL
$Results$output1[[1]]$`Scored Labels`
NULL
$Results$output1[[1]]$`Scored Probabilities`
NULL
<OUTPUT END>
Since we passed a useless test record to the web service, we got NULL responses for the "Scored Labels" and "Scored Probabilities" fields. This will not be the case once we start passing legitimate records.
Unfortunately, this code still isn't quite ready for Power BI. The output we just showed is in the form of a nested set of lists. The Power BI Query Editor needs this data to be in a data frame. We start by accessing the inner list containing the actual values.
 |
| Result List |
result.list <- fromJSON(result)$Results$output1[[1]]
result.list
<CODE END>
This code is relatively simple. From right-to-left (inner-to-outer), this code accesses the first element in the "output1" list contained within the "Results" list contained within the list returned by parsing the JSON in the "result" variable. Now, let's try to cast this to a data frame.
| Result Data Frame (Naive Attempt) |
 |
| Result List (with NAs) |
result.list[sapply(result.list, is.null)] <- NA
result.list
<CODE END>
This function enters an "NA" value into each element of the list that contains a NULL "value". Now, we can cast this to a data frame with no issues.
| Result Data Frame |
result.df <- data.frame(result.list)
result.df
<CODE END>
Now that our code returns a data frame, we need to use it in Power BI. In order to do that, let's switch over to Power BI and connect to the "Customers_New" table in our Azure SQL Database.
 |
| Customers_New |
Second, we could use an R Script in the Query Editor, which we've also talked about in a previous post. This would allow us to utilize the web service only during model processing and store the values within the data model itself for aggregation and manipulation as we see fit.
Before we can successfully run our code in the Power BI Query Editor, we need to make a few alterations to our code. We start by replacing the manually-created "reg" list with one that we create from our input dataset, which Power BI conveniently calls "dataset".
<CODE START>
req = list(
Inputs = list(
input1 = setNames(lapply(split(dataset, seq(nrow(dataset))), FUN = as.list), NULL)
),
GlobalParameters = setNames(fromJSON('{}'), character(0))
)
<CODE END>
It's important to note that the syntax here is extremely important. While it is possible to put "Inputs" and "input1" inside single-quotes, this changes the metadata of the list structure and could cause the web service call to fail. This was a particularly frustrating issue to debug.
As for the code, we start by using the "split()" function to split the "dataset" dataframe into a list such that each element in the list is a row from the original dataframe. The "seq(nrow(dataset))" provides the mapping to ensure that each element in the dataframe is split to the correct element in the list.
Then, we use the "lapply()" function to apply the "as.list()" function to each element in the list. This turns each dataframe in the list into a nested list containing the data from that record of the dataframe. Finally, we need to remove the names from the outer list using the "setNames()" function with the "NULL" parameter. This nested listed is then assigned as a nested list called "input1" within a list called "Inputs" within another list called "req". This creates the nested structure required by the web service.
Next, we rewrite the error-handling at the end to send an error dataframe to Power BI if an error occurs.
<CODE START>
if (httpStatus >= 400)
{
result.error <- data.frame("Error")
}
print("Result:")
result = h$value()
print(fromJSON(result))
<CODE END>
We accomplished this by using the "data.frame()" function to create a basic dataframe called "result.error" that contains a single record, "Error".
Next, we need to alter the code to output the final result as a data frame, instead of simply printing the JSON.
<CODE START>
if (httpStatus >= 400){
result.error <- data.frame("Error")
}else{
result.json = h$value()
result.list = fromJSON(result.json)$Results$output1
result.list.final <- lapply(result.list, FUN = function(x) lapply(x, FUN = function(y) if( is.null(y) ){y <- NA}else{y <- y}))
result.df <- data.frame(do.call(rbind.data.frame, result.list.final))
}
<CODE END>
We aren't afraid to admit that getting this right took us some time. We start by assigning the JSON output from the web service to the "result.json" object. Then, we use the "fromJSON" function to parse the results and save them as a list called "result.list". There's one caveat here. If the web service returns any NULL values, then this list will contain those NULL values. As we mentioned earlier in this post, NULL in R means that the object itself does not exist, which causes errors later on. Instead, we need to assign NA to these values. We accomplished this by nesting an if statement within two levels of "lapply" functions. Finally, we can cast our list as a data frame using the "data.frame", "do.call" and "rbind.data.frame" functions.
Here's the full script.
<CODE START>
library("RCurl")
library("rjson")
# Accept SSL certificates issued by public Certificate Authorities
options(RCurlOptions = list(cainfo = system.file("CurlSSL", "cacert.pem", package = "RCurl")))
h = basicTextGatherer()
hdr = basicHeaderGatherer()
req = list(
Inputs = list(
input1 = setNames(lapply(split(dataset, seq(nrow(dataset))), FUN = as.list), NULL)
),
GlobalParameters = setNames(fromJSON('{}'), character(0))
)
body = enc2utf8(toJSON(req))
api_key = "" # Replace this with the API key for the web service
authz_hdr = paste('Bearer', api_key, sep=' ')
h$reset()
curlPerform(url = "", # Replace this with the URL for the web service
httpheader=c('Content-Type' = "application/json", 'Authorization' = authz_hdr),
postfields=body,
writefunction = h$update,
headerfunction = hdr$update,
verbose = TRUE
)
headers = hdr$value()
httpStatus = headers["status"]
if (httpStatus >= 400){
result.error <- data.frame("Error")
}else{
result.json = h$value()
result.list = fromJSON(result.json)$Results$output1
result.list.final <- lapply(result.list, FUN = function(x) lapply(x, FUN = function(y) if( is.null(y) ){y <- NA}else{y <- y}))
result.df <- data.frame(do.call(rbind.data.frame, result.list.final))
}
<CODE END>
Now that we have updated the R code to run within the Power BI Query Editor, we can see that the resulting dataframe contains the predicted values.
 |
| Final Results |
Brad Llewellyn
Service Engineer - FastTrack for Azure
Microsoft
@BreakingBI
www.linkedin.com/in/bradllewellyn
llewellyn.wb@gmail.com
No comments:
Post a Comment