Stream Analytics is an Azure service for processing streaming data from Event Hub, IoT Hub or Blob Storage using a familiar SQL-like language known as "Stream Analytics Query Language". This language allows us to interpret JSON, Avro and CSV data in a way that will be very familiar to SQL developers. It is also possible to aggregate data using varying types of time windows, as well as join data streams to each other or to other reference sets. Finally, the resulting data stream can be output to a number different destinations, including Azure SQL Database, Azure Cosmos DB and Power BI.
We understand that streaming data isn't typically considered "Data Science" by itself. However, it's are often associated and setting up this background now opens up some cool applications in later posts. For this post, we'll cover how to sink streaming data to Power BI using Stream Analytics.
The previous posts in this series used Power BI Desktop for all of the showcases. This post will be slightly different in that we will leverage the Power BI Service instead. The Power BI Service is a collaborative web interface that has most of the same reporting capabilities as Power BI Desktop, but lacks the ability to model data at the time of writing. However, we have heard whispers that data modeling capabilities may be coming to the service at some point. The Power BI Service is also the standard method for sharing datasets, reports and dashboards across organizations. For more information on the Power BI Service, read this.
In order to leverage Stream Analytics, we obviously need to start by creating a source of streaming data. In order to do this, we'll leverage some sneaky functionality with Azure SQL Database and Azure Data Factory (ADF). Basically, we want to trigger an ADF Pipeline every minute that pulls between 1 and 5 random records from our database, placing these records in Blob Storage. We'll pretend that this is our "stream". Stream Analytics will then pick up these records, process them and sink them to Power BI. The flow should look like this:
 |
| Customer Stream |
<CODE START>
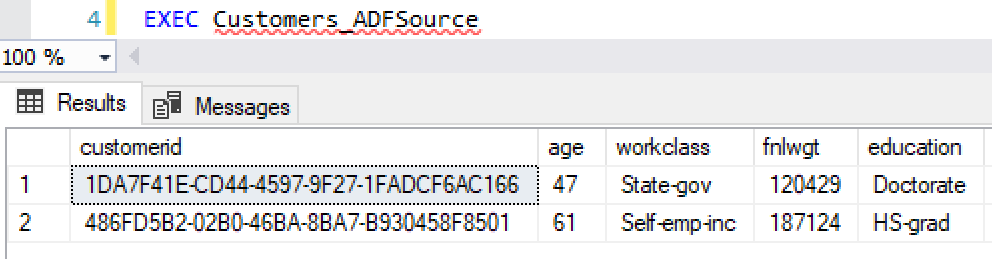
CREATE PROCEDURE Customers_ADFSource AS
BEGIN
DECLARE @records INT = ( SELECT CEILING( RAND() * 4 ) + 1 )
BEGIN
WITH T AS (
SELECT
ROW_NUMBER() OVER ( ORDER BY NEWID() )AS [rownumber]
,NEWID() AS [customerid]
,[age]
,[workclass]
,[fnlwgt]
,[education]
,[education-num]
,[marital-status]
,[occupation]
,[relationship]
,[race]
,[sex]
,[capital-gain]
,[capital-loss]
,[hours-per-week]
,[native-country]
FROM Customers_New
)
SELECT
[customerid]
,[age]
,[workclass]
,[fnlwgt]
,[education]
,[education-num]
,[marital-status]
,[occupation]
,[relationship]
,[race]
,[sex]
,[capital-gain]
,[capital-loss]
,[hours-per-week]
,[native-country]
FROM T
WHERE [rownumber] < @records
END
END
<CODE END>
EDIT: After writing this, we later found that this could also be achieved by using something similar to "SELECT TOP (@records) * FROM [Customers_New]". The parentheses are extremely important as this will not work without them.
 |
| Customers_ADFSource |
Next, we want to create an ADF Pipeline that executes the "Customers_ADFSource" Stored Procedure and loads the data into the "customerssasource" Blob Container. Showcasing this would take way too many screenshots for us to add here. Feel free to take it on as an exercise for yourselves, as it's not terribly complicated once you have the SQL Stored Procedure created.
 |
| customerssasource |
{"customerid":"5c83d080-d6ba-478f-b5f0-a511cf3dee48","age":56,"workclass":"Private","fnlwgt":205735,"education":"1st-4th","education-num":2,"marital-status":"Separated","occupation":"Machine-op-inspct","relationship":"Unmarried","race":"White","sex":"Male","capital-gain":0,"capital-loss":0,"hours-per-week":40,"native-country":"United-States"}
{"customerid":"6b68d988-ff75-4f63-b278-39d0cf066e96","age":25,"workclass":"Private","fnlwgt":194897,"education":"HS-grad","education-num":9,"marital-status":"Never-married","occupation":"Sales","relationship":"Own-child","race":"Amer-Indian-Eskimo","sex":"Male","capital-gain":6849,"capital-loss":0,"hours-per-week":40,"native-country":"United-States"}
<OUTPUT END>
We see that the ADF pipeline is placing one file containing between 1 and 5 customer records in the blob container every minute. Now that we have emulated a stream of Customer data, let's use Stream Analytics to process this stream and sink it to Power BI. We start by creating an empty Stream Analytics job. This is so simple that we won't cover it in this post.

After it's created, we see that we have four different components in the "Job Topology" section of the Stream Analytics blade. We'll start by creating an input that reads data from our Blob Container.
 |
| Create Blob Input |
 |
| CustomersSASource (SA) |
We have called this input "Customers_SASource". Next, we want to create a stream output that sinks to Power BI.
 |
| Create Power BI Output |
 |
| CustomersStream |
 |
| Query |
While writing this, we discovered that Stream Analytics will allow us to create input and outputs with underscores ( _ ) in the names, but the Query Editor considers them to syntax errors. This is an odd compatibility issue that should be noted.
Now, the last step is to go to the Power BI Portal and navigate to the workspace where we stored our dataset.
By clicking on the "CustomersStream" dataset, we can create a simple report that shows us the total number of Customers that are streaming into our dataset.
While this functionality is pretty cool, the Power BI Service still has a long way to go in this respect. Additional effort is needed to make the report always show a relative time frame, like the last 30 minutes. Reports also don't seem to automatically refresh themselves in any way. When we wanted to see the most recent data from the stream, we had to manually refresh this report. This issue also occurs if we pin a live report to a dashboard. However, we found that individually pinning the visuals to the dashboard allows them automatically update.
Now, the last step is to go to the Power BI Portal and navigate to the workspace where we stored our dataset.
 |
| My Workspace |
 |
| CustomersStreamReport |
 |
| CustomersStreamDashboard |
The left side of the dashboard shows a live report tile, while the right side of the dashboard shows a set of pinned visuals. As for our "last 30 minutes" issue mentioned earlier, we can work around this by leveraging Custom Streaming Dashboard Tiles. These tiles provide a very limited set of functionality for viewing live streaming data from a dashboard. You can read more about them here.
 |
| Custom Streaming Dashboard Tiles |
Hopefully, this post enlightened you to some of the ways that Power BI can be used to consume streaming data. The use cases for streaming data are constantly evolving, as there seem to be new opportunities every day. Stay tuned for the next post where we'll add some Azure Machine Learning Studio integration into our Stream Analytics job. Thanks for reading. We hope you found this informative.
Brad Llewellyn
Service Engineer - FastTrack for Azure
Microsoft
@BreakingBI
www.linkedin.com/in/bradllewellyn
llewellyn.wb@gmail.com
Service Engineer - FastTrack for Azure
Microsoft
@BreakingBI
www.linkedin.com/in/bradllewellyn
llewellyn.wb@gmail.com










{kind=link}
{kind=link}
{kind=link}
{kind=link}